テキストマイニング
テキストマイニングの概要
テキストマイニングとは、定性的な情報であるテキストデータを定量的に統計解析可能にするデータマイニング手法です。テキストデータからその文書情報に含まれる単語を抽出し、単語を軸にした集計や統計解析に基づいて、文書に記述されている傾向を可視化します。
テキストマイニングの基本技術
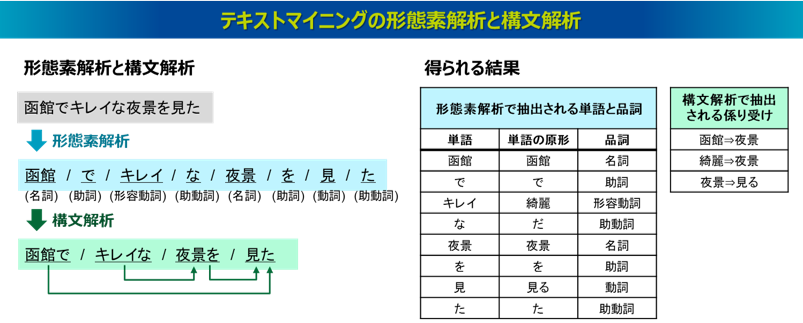
テキストマイニングには「形態素解析」と「構文解析」という2つの基本技術があります。
①形態素解析
形態素解析とは、文章を単語に分割し、その単語の品詞を割り当てる技術で、「分かち書き」とも呼ばれます。正確には単語ではなく、形態素と呼ばれる意味を持つ最小単位の文字列として分割する手法ですが、実用面では、形態素ではなく単語の単位で分割されることが通例となっています。単語と形態素の違いの例として、たとえば「観光地」という単語は「観光」「地」という2つの形態素で、「宿泊施設」という単語は「宿泊」「施設」という2つの形態素で構成されます。このように、日本語の意味情報を抽出するには最小単位の形態素よりも単語の方が適しているとされます。なお、英語の文章の場合は、単語がスペースで区切られているため、日本語よりも形態素解析がしやすい言語といわれます。
②構文解析
構文解析とは、文法規則に基づいて文章の構造を解析し、単語間の関係性を識別する技術です。たとえば、主語と述語や、修飾語と被修飾語といった係り受け関係を抽出するので、「係り受け分析」とも呼ばれます。日本語の場合は単語ではなく文節を単位に係り受け関係を抽出するのが一般的です。文節とは、日本語を意味の分かる単位に区切ったもので、助詞や助動詞は名詞や動詞とセットで括られます。なお、日本の小学校では、文節は「~ね」で区切るものと教わることが多いかと思います。
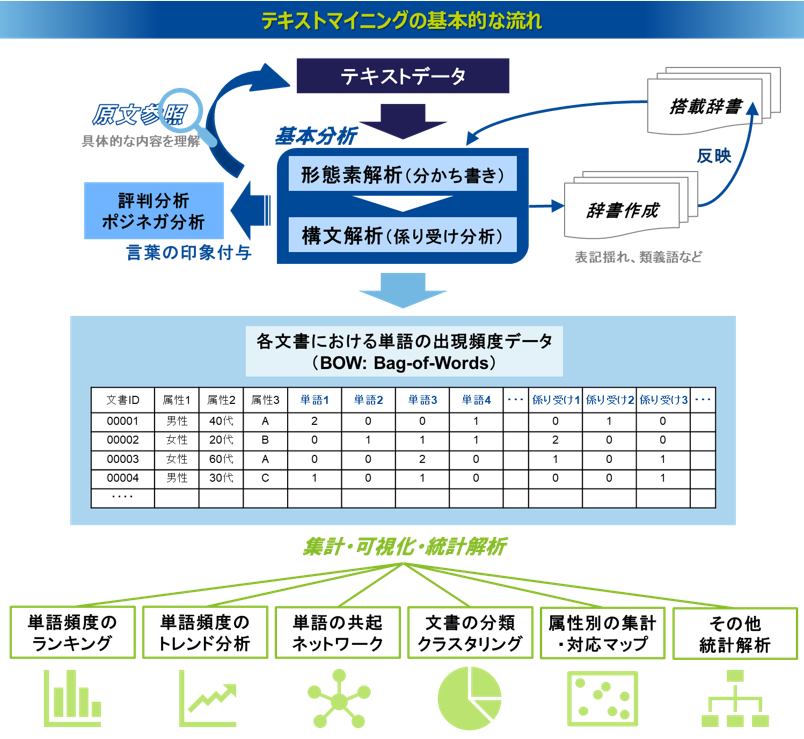
テキストマイニングは、こうした技術の処理によって、文書に含まれる単語とその品詞、また単語間の係り受け関係を抽出することができます。なお、実際に抽出される単語や係り受けは、登録されている辞書によってそれぞれ原形に変換された形で抽出されることが一般的です。形態素解析と構文解析には公開されたフリープログラムがあり、形態素解析ではJUMAN、ChaSen、MeCabなどが、構文解析ではKNPやCaboChaなどが広く知られています。
テキストマイニングにおける単語を軸としたベクトル表現
テキストデータという定性的な文書データを定量的に統計解析可能にするには、そのデータをコンピュータが処理できる数値の形式で表現する必要があります。その代表的な方法は定性的な文書をベクトルで表現するというものです。形態素解析はその最も基本的な技術で、形態素解析で文書に含まれる単語を抽出し、各文書にどの単語が何回出現したのかカウントすることで、その出現頻度という数値によって文書一つひとつをベクトルとして表現できます。このように単語の出現頻度でもって文書をベクトル化する手法をBag-of-Words(BoW)と呼びます。Bag-of-Wordsのベクトル表現は「文書×単語」という行列形式のデータで考えると分かりやすいです。一つの行に一件の文書を、一つの列に一つの単語を取ったとき、各セルの値はその文書内におけるその単語の出現回数を示します。以下の図は、ホテルの口コミデータを対象にBag-of-Wordsの例を示したものです。Bag-of-Wordsは最もシンプルな文書のベクトル表現ですが、この処理だけでもテキストデータのさまざまな定量分析が可能になり、とても強力な処理手段です。テキストマイニングのツールで実行される可視化や統計解析は基本的にこのデータ形式をベースにしています。

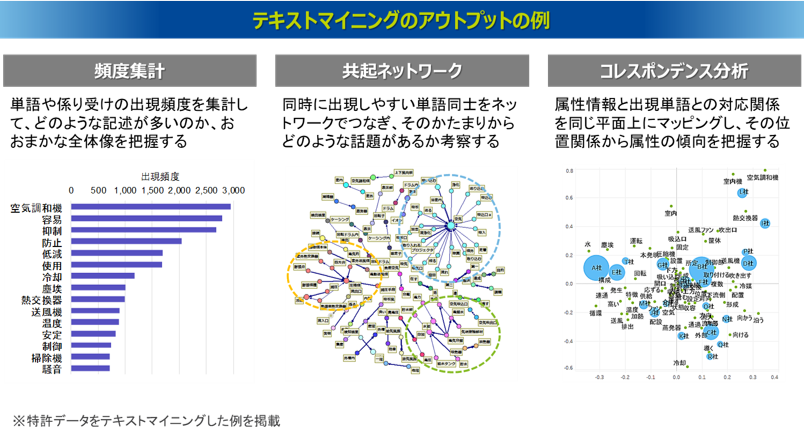
テキストマイニングのアウトプットの例
①単語の頻度集計
②共起ネットワーク
③コレスポンデンス分析
テキストマイニングの基本的な流れ
テキストマイニングの適用シーン
ビジネス現場では、さまざまなテキストデータが収集・蓄積されており、テキストマイニングの適用シーンは多岐にわたりますが、たとえば以下のような活用が考えられます。
アンケートデータ
アンケートの自由記述欄に記載された回答情報をテキストマイニングすることで、選択式回答からは得られない回答者の生の声を把握することができます。特に消費者の属性別(性別や年代別など)の傾向や、商品の属性別の傾向を把握することで、商品企画やマーケティングなどに活用することができます。
口コミデータ
Web上の口コミのレビューコメントをテキストマイニングすることで、商品やサービスの評判を分析することができます。特に口コミは自社の商品だけでなく、他社の商品の口コミも確認できるため、口コミの特徴を競合他社と比較することで、自社商品の改善や、新商品の企画に活用することができます。キーワードの頻度の推移から話題のトレンドを把握することもできます。
コールセンターの問い合わせデータ
コールセンターの問い合わせ内容をテキストマイニングすることで、顧客のニーズやサービスの改善点を把握することができます。また、頻度の多い問い合わせについてはFAQを作成することでコール数の削減を図ったり、経験の浅いオペレータのマニュアルの作成にも活用できます。
営業日報データ
営業マンの営業記録をテキストマイニングすることで、成績の良い営業活動における特徴的なキーワードを把握することができます。成約要因を把握し、営業教育に活用できます。
特許文書データ
公開されている特許の文書をテキストマイニングすることで、技術キーワードのトレンドを把握したり、各企業の出願傾向や保有技術の特徴を把握することができます。研究開発のテーマ策定や、企業間提携・M&Aなどの技術戦略の検討にも活用できます。
企業レポート
有価証券報告書などの企業レポートをテキストマイニングすることで、各社が注力している経営課題の特徴や、そのトレンドを把握することができます。差別化を図った競争優位な経営戦略を検討したり、投資先の検討にも活用できます。
ヒヤリハットレポート
製造工場などで記録されたヒヤリハットレポートをテキストマイニングすることで、現場で頻出するリスクを把握することができます。現場の安全性向上のための対策検討に活用できます。