テキスト分析技術
テキストデータ分析のテーマ
当社では、文章で記されたテキストデータの分析と活用を最も得意としており、多くのご提供実績があります。また、テキストデータの新しい分析技術の開発にも取り組み、現在3件の特許を取得しており、学会での受賞実績も複数あります。
定性的なデータであるテキストデータには多くの情報が含まれており、そこには今まで気づかなかった有用な知見が隠れている可能性が大いにあります。ビジネスの課題解決において、こうしたテキストデータを分析することは、重要なインサイトの獲得が期待できる取り組みです。特に当社が分析の対象としてよく用いるテキストデータには、「特許データ」や「VOCデータ」があります。たとえば、特許文書のテキストデータを分析することで、競合他社の技術動向を把握し、自社の研究開発計画を検討したり、M&Aなどの経営戦略に活かすこともできます。また、VOC(Voice of Customer)という顧客の声が記録されたテキストデータを分析することで、顧客ニーズを把握し、顧客志向の経営に活かすことができます。たとえば、アンケートの自由記述データを分析すれば、通常の選択式回答だけでは得られない回答者の潜在的なニーズを把握することができるため、マーケティング戦略に活かすことができます。口コミと呼ばれるWebレビューのコメントデータを分析すれば、競合他社の商品と比較しながら消費者の評価を把握でき、現状商品の改善や新たな商品企画に活かすことができます。また、コールセンターに寄せられた問い合わせ内容のデータを分析すれば、顧客の要望や不満の内容とその動向を把握でき、自社の商品やサービスの改善に活かすことができます。
当社がご提供する「特許データ分析」と「VOCデータ分析」の具体的なアプローチについては、以下のページをご参照ください。


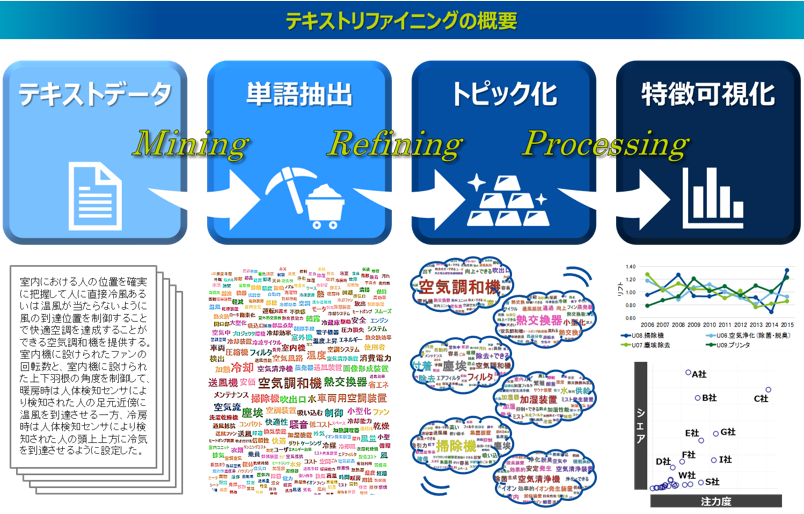
テキストマイニングとトピックモデル
テキストマイニングという手法
こうしたテキストデータを分析する代表的な手法にテキストマイニングがあります。テキストマイニングは、テキストデータに含まれる単語を抽出すること(形態素解析)を基盤技術として、その単語をベースにテキストデータ全体に潜む特徴を可視化するデータマイニング手法です。テキストマイニングは現在多くのツールが存在し、専門知識がなくても分かりやすいインタフェースで直感的な操作が可能で、ビジネスの現場では人気のある分析ツールの一つです。
テキストマイニングでよくあるアウトプットを以下の図にまとめてみました。たとえば、もっとも単純な分析は単語の頻度集計です。抽出された単語の出現頻度を集計しランキングすることで、どのような記述が多いのか全体像を把握します。また、同じ文章の中で同時に出現しやすい単語同士をネットワークでつなぐ共起ネットワークという分析があります。ネットワークでつながる単語のかたまりから、どのような話題が形成されているのか考察します。さらに少し高度な分析として、コレスポンデンス分析(あるいは数量化Ⅲ類)というものもあります。これは、抽出した単語とテキストデータに紐づく属性情報(たとえばアンケート回答者の性別・年代、特許データの出願年や出願人など)を同じ平面上にマッピングしたものです。そのマップの位置関係からそれぞれの属性の傾向を把握します。

テキストマイニングの複雑性の問題
テキストマイニングを使えば、なかなか人間では読み切れないテキストデータでも、その全体の記述傾向を可視化し、現状を把握することができます。しかし、テキストマイニングの分析は単語をベースに可視化をするため、対象となるテキストデータがビッグデータになると抽出される単語も膨大となり、結果がとても複雑で解釈が難しいという問題が生じます。これではビジネスの課題解決における有用なインサイトを得ることが困難となります。
その解決策として、抽出される単語を大幅にフィルタリングすることがありますが、これでは頻出する単語しか分析対象とできず、新たな気づきとなるような個別性の高い特徴を把握することができません。また、抽出された大量の単語を人が意味的にグルーピングすることで、いくつかのカテゴリを作成し、そのカテゴリをベースにシンプルに可視化する対策もよく取られます。しかし、そのグルーピングは属人的なものですし、作業負荷がとてつもなく大きいという問題もあります。
トピックモデルの適用
そこで、大量の単語群を機械的に集約できる「トピックモデル」という技術を適用することが有効となります。トピックモデルは主に1990年代から2000年代初頭にかけて開発が盛んになった自然言語処理のAI技術です。「文書×単語」の行列データをインプットし、教師なし学習によって文書に潜むトピックをアウトプットします。そのトピックは文書の集合と単語の集合で構成され、使われ方の似ている単語群は同じトピックに集約されます。
トピックモデルには、LSA、PLSA、LDAといった手法があります。それぞれの手法の違いについてはこちらの解説ページを参照いただければと思いますが、LSAを確率的な枠組みで発展させたものがPLSA、PLSAをベイズ的に拡張させたものがLDAとなります。トピックモデルといえばLDAを使うことが一般的ですが、当社ではあえてPLSAを適用しています。元々LDAが開発された背景には、PLSAは観測データに完全に依存した構造となり、過学習を起こしやすく、新しい文書に対してトピックの推定ができないという課題がありました。そこでLDAはPLSAをベイズ的に拡張し(ディレクレ分布という確率分布を事前分布に導入し)、過学習を抑制して、新しい文書のトピックも推定できる構造となっています。
しかしLDAは、この事前分布のパラメータの設定によって結果が変動するため、その調整が難しく、また高い汎化性能を持つ一方で、トピックの結果が一般的で抽象度が高くなることがあります。情報検索などへの適用を想定した場合では、観測データにない文書のトピックを推定できることは確かに重要で、LDAを適用することが相応しいと考えられます。一方で、特定のテキストデータの特徴を把握することを目的とした分析では、過学習するPLSAの方が観測データに対する再現度は高く、元のデータの特徴のありのままをトピックに反映できるという考え方もできます。LDAは事前分布を仮定しているため、元のデータに対する再現度はPLSAより劣ります。加えてPLSAは、そのモデル構造も結果の内容もとてもシンプルなので、当社で重視している「人が理解し考える分析」の手法としても適していると考え、当社ではPLSAを適用しています。
「テキストマイニング×トピックモデル」でテキストリファイニング
テキストリファイニングという考え方
テキストマイニングにトピックモデルを適用するアプローチは特別新しいことではありません。実際にトピックモデルのLDAがテキストマイニングのツールに標準で搭載されていることもあります。しかし、トピックを抽出してテキストデータに含まれる話題を把握することで分析が終了してしまうケースがしばしばあります。当社はこのトピックを抽出した後の分析が重要であると考えており、テキストマイニングが単語をベースに様々な特徴を可視化したように、トピックモデルで抽出したトピックをベースに様々な特徴を可視化していきます。これによってテキストマイニングの問題であった複雑性を解消できます。つまり大量の単語を軸にするのではなく、いくつかのトピックを軸にすることで、テキストデータに潜む特徴をシンプルに把握できます。これはテキストデータからマイニング(採掘)された単語を、トピックというかたまりにリファイニング(精製)して利用するというアプローチということで、当社ではこれを「テキストリファイニング」と呼んでいます。
なお、リファイニングはマイニングよりも結果が整理されますが、リファイニングしただけでは大きな価値にはならないことに注意が必要です。そのリファイニングされた結果を使える形にプロセシング(加工)して利用することが重要です。これはデータを活用したい業務目的や解決したい課題に応じて、有効な加工の形(可視化の形)を構成しなければいけません。これによってアウトプットの価値に大きな差が生まれるものだと考えています。
また、リファイニングされたトピックをベースに分析を進める上では、そのトピックの質が重要となり、よりクリアなトピックを抽出することが求められます。ツールに搭載されたLDAをそのまま適用する場合、解釈が難しいトピックや明確に類型化できていないトピックが抽出されることがあること、トピックの対象とする単語数が多いと計算時間が長くかかること、トピック数の決め方に基準がなく論理性が十分でないこと、といった問題を経験することがあります。当社では独自の前処理を施してPLSAを実行することで、またトピック数の評価基準を設けることでこうした問題を解消し、よりクリアなトピックを数学的に最適な数で抽出することができます。
テキストデータ分析における生成AIとテキストリファイニング
テキストリファイニングは、大量のテキストデータに潜む特徴をトピックで可視化し、ビジネスの課題解決に有用なインサイトを得るための分析ですが、今の生成AI技術の性能なら、こうした分析も効率的にあるいは自動的に実行できそうな雰囲気があります。そこで、テキストデータの分析において、生成AIを使って実行する場合と、テキストリファイニングのアプローチで実行する場合で、どのようなメリット・デメリットがあるのか以下に整理してみました。
生成AIを使えば、専門知識がなくても柔軟に分析の指示ができ、すぐに結果を出力してくれますので、データ分析の業務が一気に効率化しそうですが、やはりハルシネーションやブラックボックスの問題があります。その誤りに途中で気づけばよいですが、AIに依存したまま分析を進めれば、結果的に不正確な分析で意思決定をすることになってしまう恐れがあります。また、同じプロンプトでも回答が異なるので、分析の再現性が得られません。一方、テキストリファイニングは、分析に専門知識や経験が求められ、多くの時間も必要とするので、取り組みのハードルが高くなってしまいますが、分析自体は根拠が明確で正確です。
根拠が明確でない分析結果や、ときどき誤りが生じる可能性のある分析結果では、それをどのように活用して意思決定すればよいのか、納得感のある議論がしにくくなってしまいます。データドリブンな意思決定をするには、正確にデータを分析できていることは大前提です。そのため当社では、テキストデータの分析においては、テキストリファイニングのアプローチをメインに、生成AIは補助的に活用することを推奨しています。たとえば、テキストマイニングの類義語辞書の作成における候補語の列挙や、トピックの意味解釈、可視化結果から得られる特徴の考察、業務活用のアイデア出しなど、これまで負荷の大きかった部分的な作業に生成AIを活用することはとても有効だと思います。

当社開発の独自技術
テキストリファイニングを実行する当社の独自技術
このテキストリファイニングを実行する技術として、当社では①Nomolytics、②PCSA(確率的因果意味解析)、③differential PLSAという3つの手法を開発し、特許を取得しています。
Nomolyticsは、テキストマイニングにトピックモデルのPLSAを適用し、さらに確率的因果構造モデルのベイジアンネットワークを適用した手法です(特許第6085888号)。まずはテキストマイニングとPLSAでテキストデータ全体を表現するトピックを抽出し、そのトピックを軸に特徴を可視化します。さらにそのトピックを確率変数としてベイジアンネットワークでモデル化することで、そのトピック周辺の関係構造も可視化します。これによって、テキスト情報に潜む特徴や要因関係を俯瞰する手法となります。
PCSA(確率的因果意味解析)とdifferential PLSAは、Nomolyticsのトピック抽出の機能を拡張させた手法で、Nomolyticsがデータ全体を俯瞰するトピックを抽出する技術であるのに対し、PCSAとdifferential PLSAはより特徴的で個性的なトピックを優先して抽出する手法になります。これらは、より深いインサイトの獲得を狙って開発したものです。特にPCSAは、特徴を見たいあるターゲットに特化したトピックを優先的に抽出して、そのターゲットの特徴を左右する要因を探索する手法です(特許第7221526号)。一方differential PLSAは、通常のPLSAが出現頻度の多い要素を中心とした典型的なトピックを抽出しがちであるのに対して、頻度の大小に依存しない個性的なトピックを抽出し、データ全体では埋もれがちな特徴を発見する手法です(特許第7221527号)。
Nomolyticsは当社の代表的な分析手法であり、ご提供実績も多くあります。PCSAとdifferential PLSAはややマニアックな手法なので、Nomolyticsではご満足いただけないお客様や、より深いインサイトの獲得を希望されるお客様向けにご提案しています。ただし、データ分析の取り組みでは、まずは全体像を把握することが基本的なセオリーなので、データ全体を表現するトピック抽出して全体像を俯瞰できるNomolyticsの実施をまずは推奨しています。それぞれの手法については、以下のページをご参照ください。



テキストリファイニングの適用範囲
このテキストリファイニングのアプローチは、様々な業務のテキストデータに適用できます。その中でも、当社では冒頭ご紹介したとおり、「特許データ分析」と「VOCデータ分析」において多くのご提供実績があります。その具体的なアプローチについては、以下のページをご参照ください。