決定木
決定木の概要
決定木とは、特定の特徴がよく現れるようなデータのかたまりを見つけ、その分割ルールを木構造でモデル化する教師あり学習のデータマイニング手法です。具体的には、目的変数と説明変数を設定し、目的変数の特徴が固まって存在するようなデータグループを見つけていきます。複数の説明変数を使った条件でデータを分割していくことで、そのデータ領域内における目的変数の特徴の濃度を高めていきます。言い換えますと、目的変数の特徴がなるべく偏るようなデータ領域となるように、つまりその領域内のデータのばらつきが小さくなるように、説明変数の条件を組み合わせて分割していくということです。こうして得られた説明変数の条件で構成されるデータの分岐ルール(If-Thenの条件ルール)をツリー構造で可視化する手法が決定木です。
分類木と回帰木
決定木には分類木と回帰木という2つのタイプがあります。分類木では目的変数に離散値となる質的変数を取り、回帰木では目的変数に連続値となる量的変数を取ります。なお、説明変数には質的変数も量的変数もどちらも取ることができます。分類木では目的変数(質的変数)の各カテゴリの該当割合に違いが出るようにデータを分割していきます。特に「YesかNo」「該当ありか該当なし」「1か0」といった2水準のフラグ変数を目的変数に取る例が多いです。つまり、「1:該当あり」の割合が大きく偏るようなデータ領域を見つけていきます。一方、回帰木では、目的変数(量的変数)の値が偏るように、つまり値のばらつきが小さくなるようなデータ領域を見つけていき、各データ領域内の値の平均値を期待値として評価します。決定木の分類木と回帰木それぞれの用途の関係は、回帰分析で言うロジスティック回帰分析と重回帰分析の関係に近いと言えます。回帰分析は説明変数の線形結合に基づく回帰式で目的変数の特徴を説明しますが、決定木では説明変数の条件に基づくデータの分割で目的変数の特徴を説明していきます。
より具体的に以下のイメージ図を使って分類木と回帰木について説明します。このイメージ図では、ある店舗で使えるクーポン付きDM(ダイレクトメール)を顧客に送付したときに、そのうち何割の顧客がそのDMに反応して来店したのか、そして来店した顧客はその店舗でいくら購入したのかということについて、その特徴と要因を決定木で分析した例です。

左の分類木では、目的変数は「クーポン付きDMの反応有無(1:反応あり、0:反応なし)」としており、図の中の1つの〇が1件のデータを表していて、〇の中に1か0の値が入っています。この図は変数空間上のデータの配置を表していて、ここでは40個の〇があるので40件のデータということです。そのうち28個の○に1の値が入っているので、DMが送付された40人の顧客のうち28人が反応したということです。説明変数には「送付したクーポンの割引率」や「送付した顧客の年齢」などがあったとします。例えば、クーポンの割引率が20%というラインでデータを分割すると、割引20%以上では反応する顧客が多いデータ領域(右側)が切り出されます。割引20%未満のデータ領域(左側)については、さらに年齢が32歳というラインでデータを分割すると、32歳以上では反応する顧客がやや多いデータ領域(左上)が、32歳未満では反応する顧客が少ないデータ領域(左下)が切り出されます。こうして切り出されたそれぞれのデータ領域における反応顧客の割合(反応率)には偏りが生まれます。このデータの分岐ルールをツリー構造で可視化したものが決定木のアウトプットになります。
右の回帰木では、先ほどの分類木でDMに反応した顧客28件について、その顧客が店舗に来店したときにいくら購入したのかということを対象としたもので、目的変数は「来店顧客の購入金額」としています。先ほどと同様に変数空間上のデータの配置を示す図では、1つの〇が1件のデータを表していますが、回帰木では目的変数は量的変数になるため、〇の中には購入金額(単位:千円)という連続値が入っており、〇の大きさはその値の大きさに対応しています。今回は説明変数に「顧客の昨年の来店頻度」や「顧客の年齢」などがあったとします。例えば、昨年の来店頻度が16回というラインでデータを分割すると、16回以上では購入金額が多いデータ領域(右側)が切り出されます。来店頻度16回未満のデータ領域(左側)については、さらに年齢が48歳というラインでデータを分割すると、48歳以上では購入金額がやや多いデータ領域(左上)が、48歳未満では購入金額が少ないデータ領域(左下)が切り出されます。こうして切り出されたそれぞれのデータ領域における購入金額はばらつきが小さく偏っており、それぞれの平均購入金額にも大きな差が現れます。決定木では、こうしたデータの分岐ルールをツリー構造で可視化します。
決定木のツリー図では、それぞれのデータグループを「ノード」、特に最初のデータ全体を指すノードを「ルートノード」、分岐が止まった一番末端にあるノードを「リーフノード」とか「ターミナルノード」といいます。またあるノードに対して、分岐前のノードを親ノード、分岐後のノードを子ノード、ツリーの枝となる分岐のラインを「エッジ」といいます。
決定木のメリット
決定木はデータ分類のクラスタリングや予測・判別のモデリング、要因関係の可視化など、さまざまな分析目的で適用できる万能ともいえるデータ分析手法で、以下に挙げるような多くのメリットがあります。
①教師ありのクラスタリングを実行できる
データクラスタリングは通常教師なし学習を実行し、データ全体の特徴からそのデータをいくつかのクラスタに分類するもので、何か分類のターゲットを定めているわけではありません。一方、決定木ではある目的変数に対して特徴的な分類を見つけることができます。例えば売上の規模に応じたデータ分類を売上以外の変数を使って実行したり、リピート率の高さに応じた顧客分類をリピート率以外の変数を使って実行するということができます。つまりビジネスアクションに直結するようなターゲット指標(目的変数)に対して、最も効果的なデータ分類の仕方を他の説明変数を使って導くことができます。
②ターゲットに対して最も効果的な切り口を発見できる
目的変数に定めたターゲットに対して、最もその特徴が現れるような詳細な条件ルール、複合要因、セグメントを見つけることができます。つまりデータの中から最も注目したい領域の切り口を見つけることができます。特にある条件とある条件が揃うことで効果が発揮されるという場合でも、そうした複合条件として抽出できます。例えば、リピート率が高い顧客属性は女性であることが分かっていても、単純に女性というだけでなく、女性のうち特にリピート率が高いのは20代30代であり、さらにその中でも未婚者のリピート率が高いということや、逆に女性の50代60代はリピート率が低いということ、しかしその中でも水曜日に発行されるクーポンを受け取るとリピート率が上昇するということなど、効果を高めるより詳細な条件を導出することができます。これにより、どのような顧客をターゲットにすべきか、どのような施策が効果を発揮するのかという戦略を講じることができます。
データ分析ではよく層別の分析という、属性の条件別に分けた分析をします。例えば全体で相関係数を求めて相関が低い場合でも、男性と女性に分けて相関係数をそれぞれ求めると高い相関が得られるというように、全体では特徴が見えなかった結果も、属性別に分析することで意味のある結果が得られることが多くあります。たいていそのような層別の分析では、分析者の仮説に基づいて分析の切り口を探していきます。ただ、人間が検討できる層別はせいぜい1階層程度ですし、そうした切り口は人間の経験や感覚のバイアスがかかったものとなりがちです。決定木ではその有力な切り口を複数階層で探すことができ、またそこには客観性もあります。これはビジネス場面ではとても有用なことが多いものと思われます。
③ターゲットに対して最も効果的な量的説明変数の閾値を計算できる
上記のメリットにも共通することですが、ターゲットに対して効果的な切り口を探索する場合、その切り口の対象となる変数が量的変数であれば、通常は人間の経験的な閾値を採用した切り方が検討されます。例えば商品購買に対して、年代であれば、10代、20代、30代というように10歳刻み、商品の価格であれば1,000円未満、1,000円~3,000円、3,000円~5,000円というように数千円刻み、というようにその閾値の切り方が正しいかどうかは分からないものの、何となくキリが良いという理由でこうした切り方が採用されることが多いかと思います。しかし実際は、年代は22歳以下、23歳~28歳、29歳~36歳という切り方のほうが商品購買の特徴をうまく説明できているかもしれませんし、この年代の切り方の閾値も商品の価格によって変動するかもしれません。決定木ではこうした量的変数について、ターゲット(目的変数)に対して最も効果的な切り方の閾値を自動で計算することができ、その閾値も各条件によって最適なものを見つけてくれます。これはビジネス課題にデータ分析を活用する上でかなり強力な機能といえます。たとえば機械の稼働ログデータから機械の故障予測や保守点検などに決定木を活用することを考えた場合、機械のどのセンサの値がどれくらいの値を超えると故障率が上昇するか、つまりアラートを出すべきセンサの閾値はいくつかといったルールを見つけることができます。
④非線形処理のため、線形関係のない現象でも特徴を抽出できる
例えばリピート率と年齢の関係を分析する場合、データ分析の入門とも言える回帰分析などでは、リピート率と年齢に線形関係(比例関係)があることで初めて効果があると判定されます。一方、決定木では、年齢の中でも25歳近辺と40歳近辺に限ってリピート率が高いといったように、線形関係になくても効果が強く現れる特定の領域を見つけることができます。
⑤高次元なデータでも比較的高速に計算できる
これは分析に使用するPCのスペックや分析ツールにも依存しますが、決定木ではとても多くの変数で構成される高次元なデータでも比較的高速に分析ができます。より効果的な分岐ルールを発見するため、元々ある説明変数に加えてその派生変数も多量に作成し、数百数千ほどの説明変数に対して分析することもあります。
⑥外れ値の影響が少ない
決定木では、データを分割することによって特徴を顕在化させるため、データの中に外れ値となるような異常に高い値や異常に低い値があったとしても、単に外れ値を含むデータブロックとして分割されたり、外れ値のある領域だけが除外されるように分割されたりするので、外れ値の影響が少ない手法といえます。
⑦結果が視覚的に見やすい
決定木は分析過程や抽出ルールがツリー構造に可視化されるので視覚的に見やすく、その結果を解釈しやすいこともメリットの一つです。例えば社内で分析の専門知識がない人に分析の結果や効果を説明するという場面においても、他の分析手法と比べて説明がしやすく、理解も得られやすいものと思われます。
データ分析には様々な分析手法がありますが、困ったらとりあえず決定木、と言ってもよいくらい決定木は万能な手法だと思います。そのためさまざまな適用シーンで活躍し、例えば来店頻度の高い優良顧客を過去の購買情報や顧客属性から分類したり、コンビニの好調店と不振店を売場面積や駐車面積から分類したり、ゴルフ場の来客数を天気や気温、湿度、風の強さから予測したり、がんの発症確率を患者の属性や検査値、生活習慣から予測するなど、多様な適用事例が存在します。
決定木の例
たとえば以下の図のように、あるサプリの商品について初回お試し購入をした顧客が継続して同商品を購入したか否かに関するデータに決定木を適用した例を使って、決定木のアウトプットの理解をより深めていきたいと思います。

今回は初回お試し購入をした全10,000人の顧客の購買データで、この商品を継続して購入しなかった人が5,000人、継続して購入した人が5,000人いたとします。この継続購入が目的変数となり、0:継続購入しない、1:継続購入するという2つのクラスを持つ質的変数となります。説明変数には、顧客情報として、性別、年齢、職業、また他商品Aを購入しているどうかという、質的変数と量的変数の両方があります。このデータ分析によってこの商品の継続購入の可能性が高い顧客層を特定し、マーケティング戦略を検討したいと考えます。
決定木では、目的変数の特徴が色濃く出るように、つまり継続購入の0と1のデータがどちらかに偏るように分岐がされていくわけですが、それがうまく分かれるような説明変数、つまり関連性の強い説明変数から分岐がされます。まず性別という説明変数で、男性のグループと女性のグループに分割されました。男性のグループは4,000人で、そのうち継続購入しないが2,500人、継続購入するが1,500人と、継続購入しないほうに偏ったグループとなります。一方、女性のグループは6,000人で、そのうち継続購入しないが2,500人、継続購入するが3,500人と、継続購入するほうに偏ったグループとなります。
決定木のツリー構造では、上位の階層にあるノードが必ず条件となります。男性のグループの下の分岐では、男性という条件下での分岐となります。この男性という条件下では、他商品Aを購入しているか否かという説明変数で分岐がされています。男性全体では継続購入しないほうに偏っていましたが、男性が他商品Aを購入している層では、継続購入しないが600人、継続購入するが900人と、継続購入するほうに偏ったグループに変化しています。一方、男性の他商品Aを購入していない層では、継続購入しないが1,900人、継続購入するが600人と、継続購入しないほうにより偏っています。さらに男性でかつ他商品Aを購入していないという条件下での分岐を見ますと、年齢が41歳というラインで分岐がされ、男性かつ他商品Aを購入していないかつ41歳以上であると、継続購入しないが300人、継続購入するが400人と、サンプル数は少ないですが継続購入するほうに偏っているグループとなります。また、男性かつ他商品Aを購入していないかつ41歳未満であると、継続購入しないが1,600人、継続購入するが200人と、大きく継続購入しない方に偏ったグループになることが分かります。先ほども述べましたが、決定木では年齢といったような量的な説明変数については、目的変数に対して最も効果的な分岐の閾値を自動で計算してくれることが大きなメリットといえます。今回も41歳というラインが継続購入に最も影響を与えるということを機械が探索してくれましたが、これを人間が発見するのはなかなか難しいかと思います。
続いて、女性のグループの下の分岐についても見てみます。女性全体で見ますと、継続購入する方が多いですが、これがまず年齢という説明変数で分岐され、28歳と36歳というラインで3つのグループに分割されています。女性の28歳未満では、継続購入しないが700人、継続購入するが600人と、逆に継続購入しない方に偏っています。一方、女性の28歳以上36歳未満は、継続購入しないが400人、継続購入するが700人と、継続購入により偏るようになりました。また女性の36歳以上では、継続購入しないが1,400人、継続購入するが2,200人と、継続購入するほうにやや偏っています。さらに職業という説明変数で分岐されると、女性かつ36歳以上かつ会社員の層では、継続購入しないが800人、継続購入するが1,700人と、大きく継続購入するほうに偏ることになり、女性かつ36歳以上かつ会社員でない層では、継続購入しないが600人、継続購入するが500人と、継続購入しないほうにやや偏っていることが分かります。
この分析結果によって、初回お試しから継続購入の可能性が強い顧客層とは、男性では他商品Aを購入している方、あるいは他商品Aを購入していない方であっても41歳以上の方、女性については28歳以上で継続購入の可能性が高く、特に36歳以上では職業が会社員の方で継続購入の可能性がとても高いということが分かります。この結果から、こうした顧客層をターゲットに初回お試しの案内やキャンペーンを打つなどのマーケティング戦略を検討することができます。
決定木のアルゴリズム
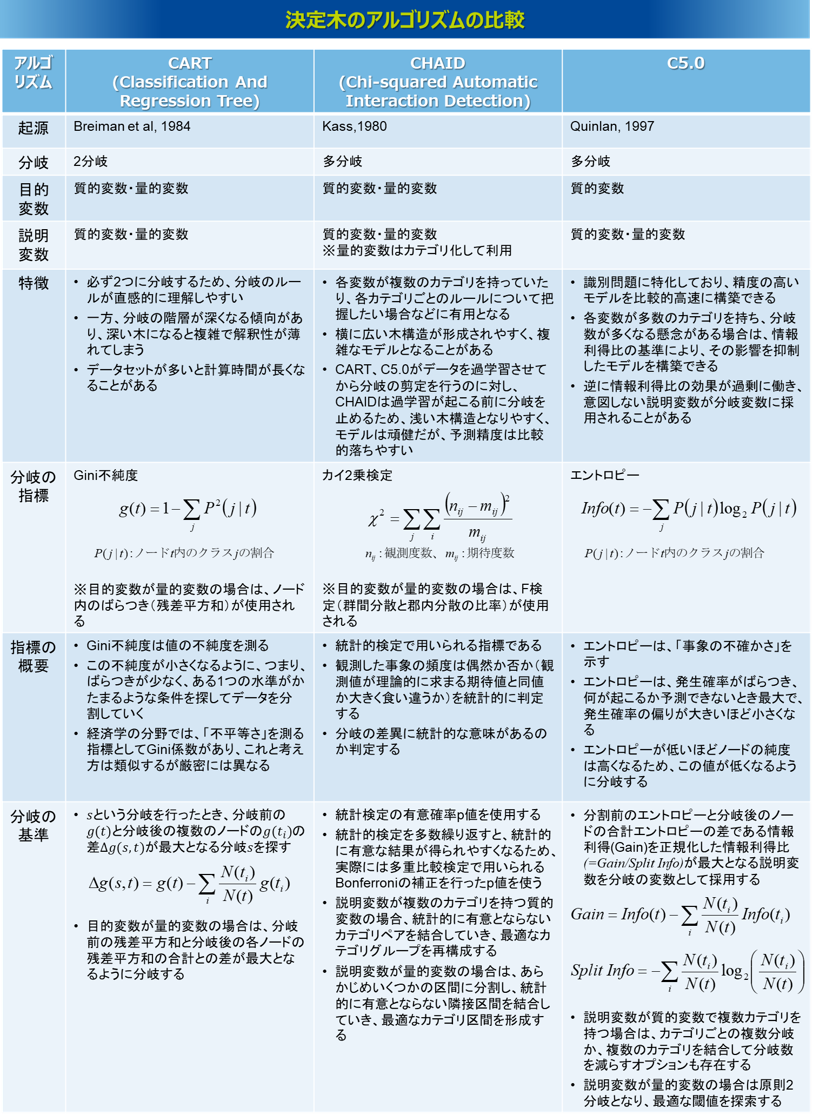
一言で決定木と言っても様々なアルゴリズムがあり、それぞれ条件や特徴が異なります。ここではよく使用される3つのアルゴリズムCART、CHAID、C5.0を紹介します。
CARTは、分岐される数が必ず2つとなることが特徴です。分岐の指標にはGini不純度を使います。Gini不純度は値の不純度を測る指標で、この不純度が小さくなるように分類していきます。つまり、ばらつきが少なく、ある1つの水準がかたまるような条件を探してデータを分割していきます。経済学の分野では、「不平等さ」を測る指標としてGini係数がありますが、これと考え方は類似しますが厳密には異なるので、CARTではGini係数と区別してGini不純度と呼ばれます。また、目的変数が量的変数の場合は、ノード内のばらつき(残差平方和)を分岐の指標に用います。この場合は、分岐前の残差平方和と分岐後の各ノードの残差平方和の合計との差が最大となるように、つまりその減少量が最大となるように分岐が形成されます。なお、説明変数が質的変数で、そのカテゴリ数が3水準以上ある場合は、2グループに分類した各パターンでGini不純度の評価をし、最も評価の良い分類を採用します。説明変数が量的変数の場合は、値をソートし、最もGini不純度の評価が高まる閾値を逐次的に探索していきます。CARTは必ず2つに分岐されるため、分岐のルールが直感的に理解しやすいというメリットがあります。ただし、分岐の階層が深くなる傾向があり、深い木になると複雑で解釈性が薄れてしまうことに注意が必要です。
CHAIDは、CARTが2分岐だったのに対し、一度に複数の分岐ができます。説明変数は主に質的変数となりますが、量的変数もカテゴリ化によって使用できます。分岐の指標には、目的変数が質的変数の場合は、カイ2検定を使い、その分岐の差異に統計的な意味があるか判定します。目的変数が量的変数の場合は、同じく統計的検定の手法であるF検定を用います。このとき、統計的検定を多数繰り返すと、統計的に有意な結果が得られやすくなるため、多重比較検定で用いられるBonferroniの補正をした有意確率p値で判定を行います。なお、説明変数が複数のカテゴリを持つ質的変数の場合、まずはこれらをまとめることによって、より少ないカテゴリグループで構成できないか検定します。具体的には、各カテゴリのペアに対して補正後のp値を計算し、p値が最も高く統計的有意とならないペアを結合していき、これを有意差のないペアが存在しなくなるまで繰り返すことで、最適なカテゴリグループの再構成を行います。また、説明変数が量的変数の場合は、分岐の計算過程の中で自動的にカテゴリ化の処理をすることもできます。その場合は、あらかじめいくつかの区間に粗く分割し(等頻度や等間隔など)、やはり有意差のない隣接区間を順に結合していくことで、量的変数の最適なカテゴリ区間を自動で形成します。CHAIDは多分岐の構造をもつため、各説明変数が複数のカテゴリを持っていたり、カテゴリごとのルールについて把握したい場合などに有用だといえますが、CARTと比べて横に広がりやすい傾向があり、場合によっては複雑な構造になることがあります。また、CARTは(後のC5.0も)、データに過学習するまで分岐を展開してから分岐の途中の枝を刈る剪定が行われますが、CHAIDは分岐の過程で過学習が起こる前に統計的に剪定する(分岐を止める)仕組みとなっていることで、浅い木構造になる傾向があり、場合によっては分岐が展開されないこともあります。そのため、頑健なモデルが構築できますが、予測精度は比較的落ちやすいです。
C5.0は、CARTやCHAIDと比べると比較的最近の手法となりますが、目的変数は質的変数に限定されます。分岐の指標はエントロピーと呼ばれる、「事象の不確かさ」を示す指標を使います。エントロピーとは、発生確率がばらついて何が起こるか予測できないときに最大で、発生確率の偏りが大きくなるほど小さくなります。得られる結果(情報)に伴い、確率の幅が狭まると減少し、結果が既知の時は最小値の0となります。決定木においては、エントロピーが低いほどノードの純度は高くなるので、この値が低くなるように分岐がされます。より具体的には、分岐前のエントロピーと、分岐後の各ノードのエントロピーの合計の差である情報利得(ゲイン)を求め、分岐の数の影響を正規化した情報利得比(ゲイン比)を判定に使います。つまり分岐の前後で、この情報利得比が最大となる説明変数が分岐の変数に採用されます。説明変数が質的変数で複数のカテゴリを持つ場合は、原則としてそのカテゴリ数による複数分岐になりますが、複数のカテゴリを結合して分岐数を減らすオプションも存在します。説明変数が量的変数の場合は原則2分岐となり、量的変数の値をソートしたうえで、最も情報利得比が高まる閾値を逐次的に探索していきます。C5.0は、識別問題に特化しており、精度の高いモデルを比較的高速に構築できるといわれます。また、CHAIDのように多分岐の構造をとるため、各変数が複数のカテゴリを持っていたり、カテゴリ(範囲)ごとのルールについて把握したい場合などに有用だといえます。特に、変数のカテゴリ数が多数あり、分岐数が多くなってしまう可能性がある場合は、C5.0は情報利得比の基準によって、その影響を抑制することができます。ただ、C5.0は、正規化された情報利得比であっても分岐数の多い説明変数で高い評価を得て選択されることがあったり、逆に情報利得比の効果が過剰に働いて、本来意味のあるはずの多水準変数でも過小評価されたり、意味のない2水準変数が過大評価されることもあります。
決定木はこうした特徴の異なるアルゴリズムによってアウトプットも異なります。そのため、どの手法を使えばよいのかという問いが多く発生します。その回答としては、どれが正解ということではなく、どれも正解であり、その選択に迷うときはそれぞれ実行してそれぞれの結果を確認し、設定したビジネス課題や適用業務との合致性を考慮しながら、現場で納得のいく分析結果を選択するということで良いと思います。当社の経験的には、データの要因構造を把握したいときはCHAIDが、質的変数の識別モデルとして高い精度のモデルを構築したいときはC5.0が、その中間の用途として、質的・量的両方の予測モデルとして使ったり、シンプルな要因構造を把握したいときはCARTが使いやすいように感じます。
要因把握の決定木と識別予測の決定木
決定木は先述の通り、目的変数の特徴が色濃く現れるように、つまりその特徴にデータが偏るように説明変数を使ってデータを分割し、その分岐ルールをツリー構造でモデル化する教師あり学習のデータマイニング手法になります。アウトプットがツリー構造で可視化されるため、目的変数と関係が強い要因を視覚的に把握したり、その特徴が最も現れる条件ルールを把握することができます。一方、決定木はその条件ルールから目的変数の状態を予測する予測モデルとしても利用することができ、近年のAIブームではその予測精度の追求で盛んにアルゴリズム開発の研究が行われています。
決定木の予測精度を向上させる特にメジャーな方法として、バギングとブースティングがあります。バギングは、すべてのデータで1つの決定木を構築するのではなく、全データの一部をランダムにサンプリングして決定木を構築し、重複を許して学習データを何度も入れ替えながら複数の決定木を構築します。そして、得られたすべての決定木の結果を統合することで(多数決や平均を取ることで)、1回の学習に依存しない決定木のモデルを構築し、全体の予測精度を向上させるというものです。さらにデータだけでなく説明変数もランダムに入れ替えて複数の決定木を構築し、それらを統合する方法をランダムフォレストといいます。一方、ブースティングは、すべてのデータあるいは一部のデータでまず決定木を構築し、その予測結果で間違って予測されたデータの重みを重くして決定木を更新することで、その間違ったデータをうまく予測できるようにしていきます。この調整を繰り返して複数の決定木を構築し、最後にやはりそれらの結果を組み合わせることで予測精度を向上させるというものです。厳密な技術的説明は割愛しますが、このように複数の決定木を構築し、それを組み合わせることで予測精度を向上させるといったアルゴリズムの開発がされています。
確かにこうした取り組みによって決定木の予測精度は向上していきますが、一方でシンプルさが失われていきます。複数の決定木を組み合わせることで、どの説明変数のどの閾値でデータが分割され、どのような要因・条件が目的変数に影響を与えているのか、明確なツリー構造で可視化することが難しくなってしまいます。これはベイジアンネットワークの解説のなかで記載しました「識別問題のディープラーニングと現象理解のベイジアンネットワーク」に通じるところがあります。どちらの手法がよいということではなく、それぞれの特徴を理解したうえで使い分けることが求められます。つまりデータの中の要因関係を理解することよりも予測精度の高さを追及する場合はバギングやブースティングを適用することはとても有効です。一方で、業務担当者が施策を検討する示唆を得るために、ある特定の効果を発揮する要因や条件を可視化し、そのデータに潜む特徴や要因関係を理解したい場合は、予測精度は劣るかもしれませんが、シンプルに一つの決定木をアウトプットするのが良いかと思います。
決定木とベイジアンネットワーク
決定木では、説明変数の分岐条件の下において目的変数の分布を計算していきますが、実は左右対称のツリー構造を持つ決定木と子ノードが一つのベイジアンネットワークは等価となります。例えば以下の図のように、目的変数Yに対して説明変数がX1とX2の2つがあり、どの変数も0と1の2水準を持つ変数であるとしたとき、まずX1で分岐がされたそれぞれのノードに対してどちらもX2で分岐したときの決定木は、X1とX2の全組み合わせに対してYの確率分布を計算するターミナルノードができあがります。これはX1とX2を親ノード、Yを子ノードとしたベイジアンネットワークと等価になり、この場合のベイジアンネットワークの確率モデルP(Y|X1,X2)はX1とX2の全組み合わせに対するYの確率分布を計算したモデルとなります。