自然言語処理コラム
自然言語処理とは
自然言語処理(Natural Language Processing, NLP)とは、人間が使う言葉を機械で処理できるようにする技術の総称です。これを実現するためにはその言葉を機械が認識できる形式で表現する必要がありますが、その代表的な方法が、文書や単語を数字のベクトルで表現するというものです。
その「ベクトル表現」というものについて、まずは高校数学のおさらいをしたいと思います。以下の図では、x軸とy軸の2次元で表現されるAとBのベクトルがあり、それぞれのベクトルの成分は小さな表で示したようになります。ここから、ベクトルのスカラー積である内積を計算したり、その内積からAとBの間の角度のコサインを求めて、AとBの類似度を計算することができます。これはいわゆるコサイン類似度というものです。

自然言語処理におけるベクトル表現も基本はこれと同じです。今は2次元のベクトルで表現しましたが、例えば以下の図左のように、文書に含まれる単語一つ一つを軸として、その単語の出現頻度でもって文書をベクトル表現するというものがあります。また、図右のように、軸の意味も数値の意味も人間には分かりませんが、深層学習によって文脈を捉えた表現力の高い多次元のベクトルを学習させるというものもあります。
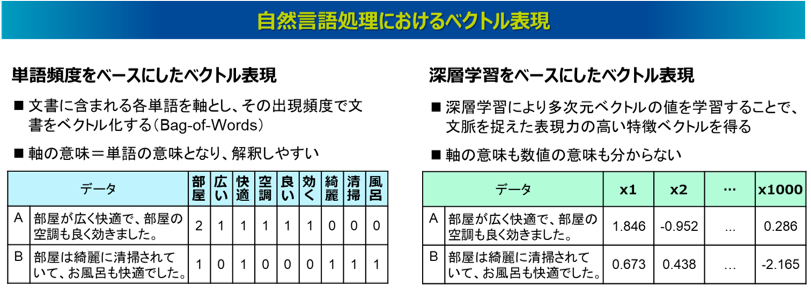
このように自然言語処理の基本は、文書や単語を多次元のベクトルで表現するというものになります。特に今のAIの自然言語処理技術では、いかに複雑で表現力の高いベクトルを獲得するかというのが技術競争の焦点になっています。
自然言語処理技術の分類と整理
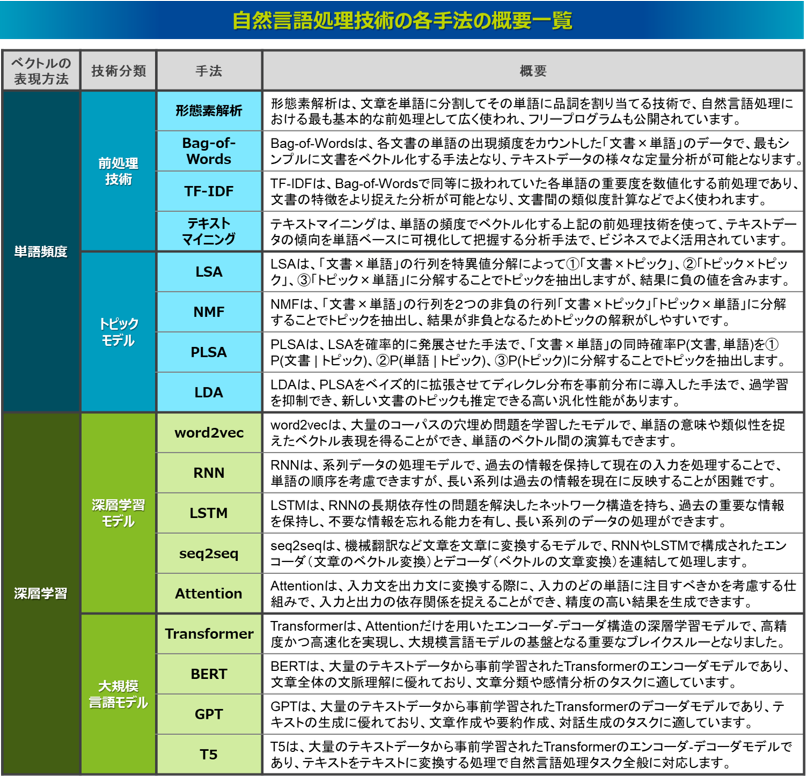
近年のAI領域における自然言語処理技術にはどのようなものがあるのか、以下の図のように分類して整理をしてみました。ここではベクトルの表現の仕方で2つに大別しています。
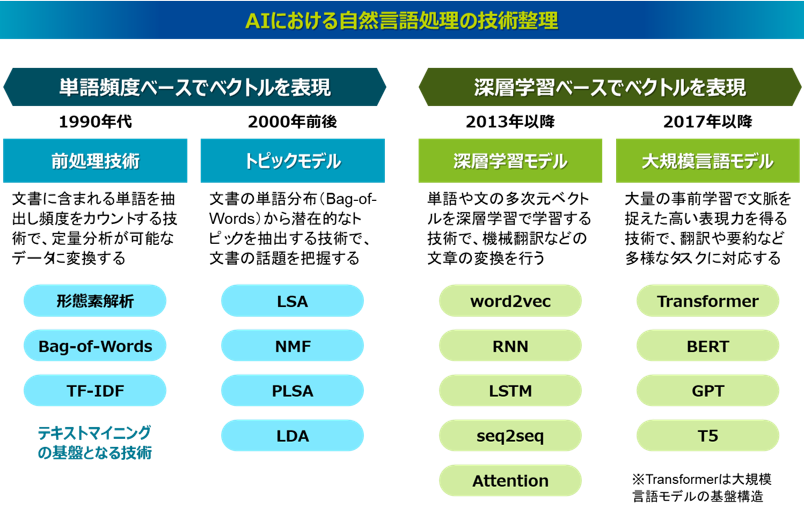
一つ目は左側の、単語の頻度をベースにベクトル表現した技術です。これを可能にする最も基本的な前処理技術に「形態素解析」があり、これは文書に含まれる単語を分解するという手法で、テキストマイニングの基盤技術になります。これによって、その単語の出現頻度でもって文書をベクトル表現できます。形態素解析は、日本では1990年代に実用的なツールが公開され、利用が進みました。そして、この単語の頻度のベクトルデータを使って、教師なし学習により文書のトピックを抽出する「トピックモデル」という技術があります。トピックモデルは主に2000年前後に開発が盛んになった技術です。


一方で右側は、主に2013年以降の第3次AIブームで登場したもので、深層学習によって複雑なベクトルを学習させる技術です。これによって、文脈を捉えた高い表現力を獲得できるようになり、文章の変換や生成といった高度な処理ができるようになりました。特に2017年に発表されたTransformerが大きなブレイクスルーとなり、2018年以降ではChatGPTに代表される大規模言語モデルの開発が盛んとなりました。


各手法の詳細な説明は専門書に委ねたいと思いますが、本コラムでは各手法の概要と特徴について簡単に解説し、自然言語処理の技術の全体像を俯瞰します。この解説で強調したいことは、どれが新しい手法でどれが古い手法であるとか、どの手法がどの手法より優っているのか劣っているのかということではなく、それぞれの手法において固有の特徴があるということです。そしてその特徴を理解した上で、今解決したい課題にはどの手法が有効であるのか見極め選択できることが重要となります。