特許データ分析
特許文書データ分析の過去と現在
従来の特許文書データ分析
企業の技術戦略を検討するうえで、その技術領域の動向を把握するために、特許情報はしばしば分析の対象とされます。通常は他社の技術開発動向は機密性が高いので、外部から確認することは難しいですが、特許情報はそれを探ることのできる貴重な公開情報です。
特許情報分析というと、従来はパテントマップと呼ばれる手法が代表的で、特許調査において長く親しまれてきました。パテントマップは主に出願人や出願年、特許分類(IPC、FI、Fタームなど)を軸にして特許件数を集計し、技術の実態や傾向を可視化したものです。また、テキストマイニングを適用することで、特許の要約文や請求項、明細書といった文書情報も活用してパテントマップを形成することもあります。
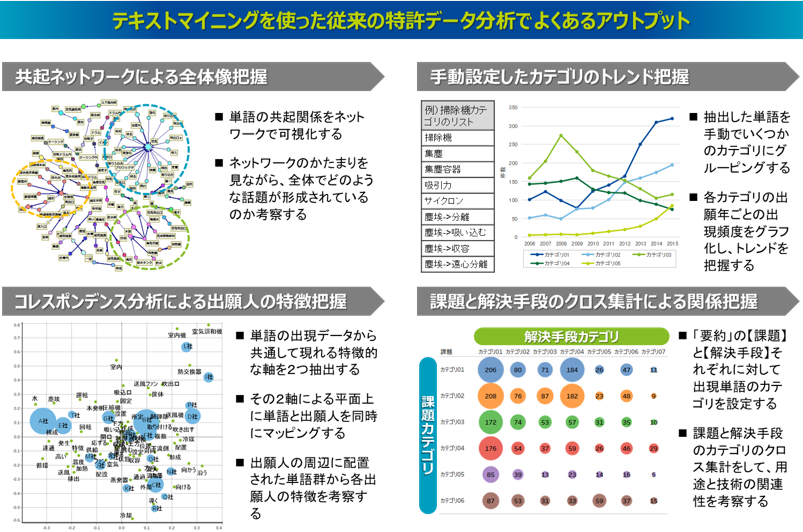
たとえば、以下の図にあるようなアウトプットがよく形成されます。まずは、特許の文書情報にテキストマイニングを実行することで、特許文書に含まれる単語を抽出して、その単語をベースに傾向を可視化していきます。たとえば、単語間の共起関係をネットワーク上で可視化することで、単語群のかたまりから技術の話題が考察されます。また、コレスポンデンス分析(あるいは数量化Ⅲ類)と呼ばれる手法を使って、単語と出願人の情報を同じ平面上にマッピングすることで、その配置状況から出願人の技術動向が考察されます。一方、こうした単語をベースに分析を進めると、単語の量が多くて結果が複雑になるので、その単語を人が意味的にグルーピングすることでいくつかのカテゴリを作成し、そのカテゴリを軸に、出願トレンドなどの傾向を可視化することもされます。また、国内で出願された特許の要約文は、「課題」と「解決手段」という項目を立てて記述されることが多いので、その記述形式を利用した分析もあります。たとえば、課題と解決手段のそれぞれの文章に対して人がカテゴリを作成し、その課題カテゴリと解決手段カテゴリのクロス集計をすることで、用途と技術の関係を考察するといったことも行われます。ある用途を実現しようとするときの解決技術の候補を探ったり、自社の技術の新しい用途を探索するといった活用がされます。実施している分析は、特許文書に含まれる単語をベースに傾向を可視化するというもので、シンプルですが直感的に分かりやすく、特許文書の全体像を把握できる有効な手段として従来から取り組まれてきました。
最近のAIを使った特許文書データ分析
最近は、AIの自然言語処理技術を適用した特許文書データ分析が活発となっており、そうした機能が搭載された特許調査ツールが当たり前となっています。自然言語処理技術とは、人間が使う言葉を機械で処理できるようにする技術のことで、それを実現するためには、その言葉を機械が認識できる数値のベクトルで表現します。テキストマイニングはその最も単純な方法を採用しており、単語の出現頻度という数値によって文書をベクトル表現しています。近年のAIを活用した自然言語処理技術では、深層学習によって高い表現力を持つ複雑なベクトルを学習しており、文脈を捉えたより精度の高い分析を実現しています。こうしたAIを活用した最近の特許データ分析では、例えば以下のような機能がよく用いられます。たとえば、入力した特許と類似度の高い特許を検索して権利侵害リスクに対応する、特許文書の内容を要約させて把握する、特許を自動で分類して整理をする、特許群の俯瞰マップを作成して各技術の位置づけを可視化するといった機能があります。

従来の分析アプローチの価値と課題
こうした深層学習のAIを活用した自然言語処理技術は、表現力の高いベクトルを獲得して精度の高い柔軟な分析ができますが、そのベクトルとは大量の数字の羅列であり、それ自体の意味については解釈できません。また、分析の処理過程はブラックボックスになってしまうため、AI分析で得られた結果に対して、現場ではなかなか納得感が得られず、意思決定の議論がしにくいというケースも少なくありません。さらに最近の生成AIでは、もっともらしいが誤っている情報を生成してしまうハルシネーションの問題や、再現性がないといった問題もあるため、結果の利用に対してさらに慎重になってしまうこともあります。
一方、古典的な自然言語処理技術であるテキストマイニングは、単語の出現頻度のみでベクトル表現をしているので、複雑な文脈は捉えられませんが、そのベクトル自体の意味はよく理解できますし、分析の過程も明確なので、最近のAIよりも扱いやすいと感じる現場もあるようです。つまり、従来のパテントマップの分析アプローチが陳腐化しているかというと、そうではありません。可視化の仕方こそ単純ではありますが、それ故にとてもシンプルで人間が容易に理解しやすく、誰もがその分かりやすい結果から着想を得ることができます。
深層学習のAIを使った分析は、自動化されたプロセスによって即座に結果が出力されるので、知財業務の効率化という面では優れているといえます。しかし、人間が考える余地は限定的で、プロセスが不透明の結果だけでは、重要な気づきを見落としてしまう可能性もあります。一方、パテントマップによる従来の分析は、その分析プロセスを通じて、分析者が理解しながら考えるアプローチとなります。人間による納得感のある技術戦略を検討するという目的では、これまで長く親しまれてきたシンプルで分かりやすいパテントマップはいまだに有用といえます。
しかし、従来のパテントマップの分析アプローチは、分析対象となる特許データの量が多くなると対応が難しくなる欠点があります。データ量が少なければ人手を介した丁寧な分析もできますが、データ量が多くなるとこれを人間が一つひとつ実施することは難しく、分析結果に主観的な偏りも生じてしまいます。特にテキストマイニングの実行では、読み込むテキストの量が多くなれば、それだけ大量の単語が抽出されるため、その単語をベースに可視化をするアプローチでは、結果がとても複雑となってしまい、解釈の容易性が損なわれてしまいます。
当社が実施する特許文書データ分析
当社では、大量の特許文書データであっても、従来のパテントマップのように分かりやすくシンプルな分析ができるアプローチを実施しています。特に、「テキストマイニング×トピックモデル」というテキストリファイニングの考え方により、従来の大量の単語をベースとした複雑な可視化ではなく、いくつかのトピックをベースにしたシンプルな可視化を実現します。さらに「ベイジアンネットワーク」という確率的な因果構造を分析するモデリング手法を適用することで、特許文書に潜む要因関係、特に用途と技術の統計的な関係を分析することが可能です。この「テキストマイニング」×「トピックモデル(PLSA)」×「ベイジアンネットワーク」で構成された当社の独自技術である「Nomolytics」を使って、特許文書データを分析するアプローチを以下の図にまとめました。
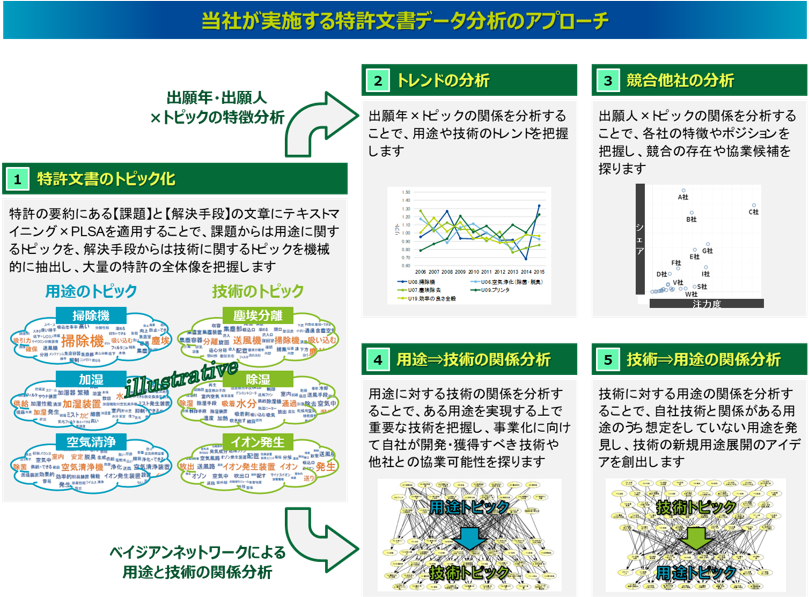
まずは、特許の文書情報にテキストマイニングとトピックモデルのPLSAを適用することで、(1)客観的な視点で特許の記述内容をトピックに類型化することができます。特に要約の課題と解決手段の文章を対象に、それぞれから用途に関するトピックと技術に関するトピックを抽出することで、母集団の特許群における用途と技術の全体像を把握することができます。これは、従来のパテントマップの分析アプローチで、人がカテゴリにまとめていた作業に該当します。人によるカテゴリ分類は、丁寧な分類ができる一方、属人的で知識継承がしにくく、また作業負荷がとてつもなく大きいという課題がありました。これに対してテキストマイニングとトピックモデルを適用することによって、特許文書に潜むトピックを機械的に抽出することができます。
また、そのトピックを軸にした特徴分析として、(2)出願年×トピックの関係を分析することで用途や技術のトレンドを把握したり、(3)出願人×トピックの関係を分析することで各トピックにおける競合他社の特徴やポジショニングを把握し、他社との棲み分けや差別化、協業、M&Aの可能性も検討できます。
さらに、ベイジアンネットワークを適用することで用途のトピックと技術のトピックの関係性を統計的に分析することができます。たとえば、(4)用途に対する技術の関係を確認することで、ある用途の事業を実現するために重要な技術や代替技術を把握し、事業化に向けて自社が開発・獲得すべき技術や他社との協業可能性を探ることができます。一方、(5)技術に対する用途の関係を確認することで、自社技術と関係がある用途のうちまだ想定していない用途を発見し、自社技術を有効活用できる新しい用途展開のアイデアを得ることもできます。従来のパテントマップの分析アプローチでも、人が作成した課題カテゴリと解決手段カテゴリのクロス集計を取ることで、用途と技術の関係が分析されていましたので目的は同じです。しかし、従来のアプローチでは、そのカテゴリが属人的であるものに加え、関係分析の方法が単純なクロス集計であることが多く、統計的な関係分析はできていないことが多くあります。ベイジアンネットワークでは、それぞれの用途がそれぞれの技術と互いにどのどのような関係を持っているのか、その統計的な因果構造を探索することができます。
当社が実施するNomolyticsを使った分析の事例やサービスの紹介資料