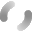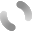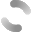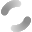VOCデータ分析
VOCデータを分析する意義
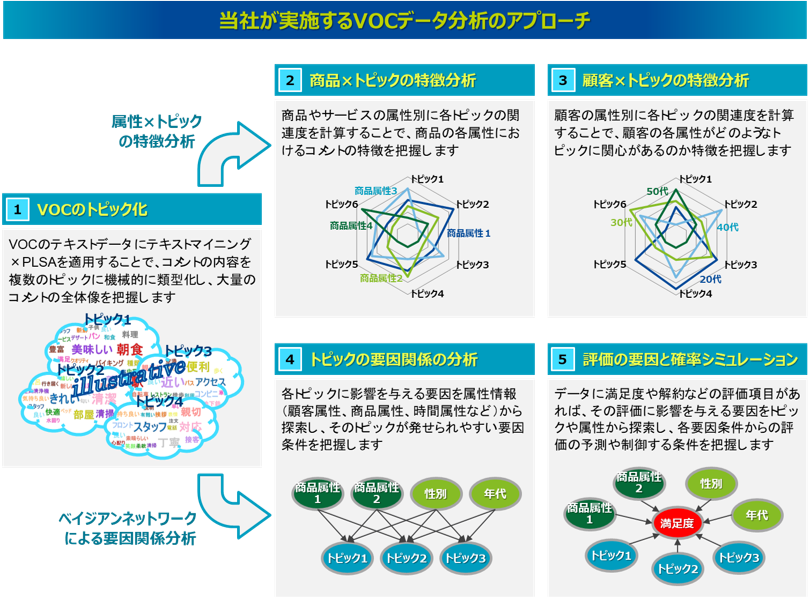
当社が実施するVOCデータ分析
当社が実施するNomolyticsを使った分析の事例やサービスの紹介資料



Nomolyticsを適用した各種VOCデータの分析イメージ
ここでは当社技術のNomolyticsをVOCデータに適用した分析イメージを、VOCデータの種類ごとに紹介します。具体的には、「自由記述付アンケートデータ」「口コミデータ」「コールセンターの問い合わせ履歴データ」の例を紹介します。
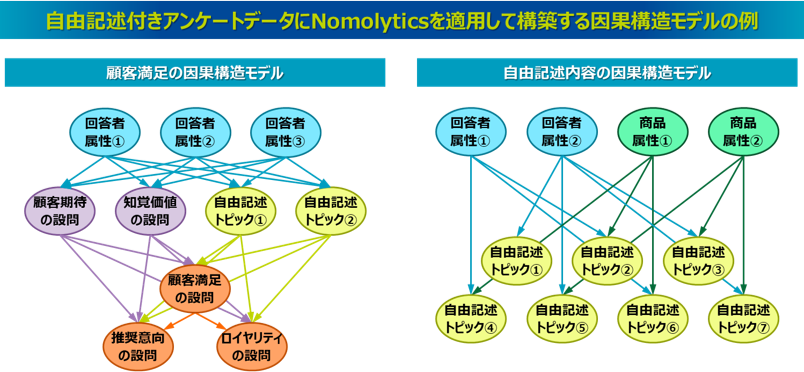
自由記述付アンケートデータの分析
アンケートデータの統計解析はよくある試みですが、選択式の設問と自由記述式の設問が両方用意されたアンケートの場合、従来は選択式の回答データのみ統計解析を実行し、自由記述式の回答データはそれだけ独立して目視で確認するか、テキストマイニングでその記述概要を把握するという、選択式回答と自由記述式回答はそれぞれ独立した分析がされがちでした。その理由は、選択式の回答は構造化されたデータであるのに対し、自由記述式の回答は構造化されていない定性データであり、そのままでは同時にまとめて統計解析を実行できないためです。アンケートにおいて、選択式の設問はアンケート設計者の仮説に基づいて選択の回答を導くものであり、その回答は受動的といえます。一方、自由記述式の回答は能動的な回答であり、回答者の生の声の情報であるため、とても貴重な情報といえます。
そこで、自由記述式の回答内容にテキストマイニングとトピックモデルを適用して、その内容をトピックに変換し、アンケートの各回答データに対するトピックの該当度を計算します。そうすることで、各トピックも他の選択式回答と同様に構造化されたデータとして扱うことができ、選択式と自由記述式の回答を一緒に分析できます。そして、そのトピックの該当度を確率変数として扱い、ベイジアンネットワークを適用すれば、アンケートの各選択式回答の結果と自由記述式回答のトピックの因果構造をモデル化できます。
こうしたモデルを用いることで、顧客は自社の商品に対してどのような期待や価値を感じ、それが満足度やロイヤリティにどのように影響を与えているのかということを、選択式回答だけでなく、自由記述回答の要因も絡めて把握でき、顧客理解をより深めることができます。またベイジアンネットワークで構築された確率モデルを利用すれば、高い顧客満足やロイヤリティの確率を高めるにはどのような価値を提供することが効果的なのかということをシミュレーションできます。
また、自由記述の回答から得られたトピックに対する因果構造をモデル化することもできます。こうしたモデルを用いることで、たとえば回答者の属性(性別や年代、職業など)や商品の属性によって、自由記述の内容がどのように変化するのかということを把握できます。そしてベイジアンネットワークで構築されたモデルを利用すれば、まだ市場に投入していない企画中の新しい商品であっても、その商品の属性情報とターゲット顧客の属性情報から、どのようなコメントが寄せられる確率が高いのかということを事前に評価できます。
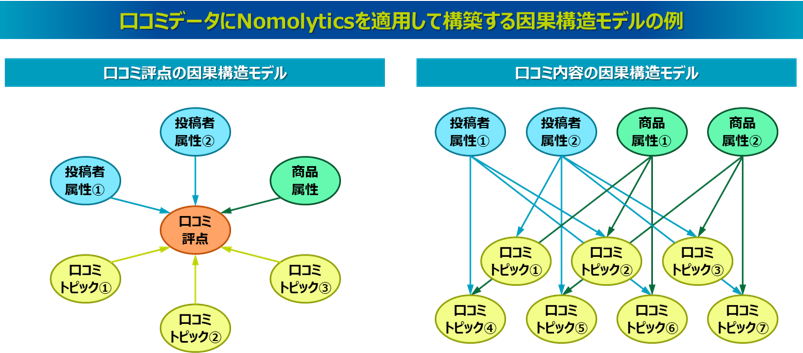
口コミデータの分析
口コミは、消費者によってWeb上に投稿された商品やサービスの評価に関する感想文形式のコメント情報です。今では宿泊施設やレストラン、観光地、家電製品、化粧品など、インターネット予約やECサイトの普及により、さまざまなジャンルの投稿情報が大量に蓄積され、Web上で閲覧できます。
口コミデータはコメントの情報と評点の情報がメインであり、性別や年代といった投稿者の属性情報が取得できるものもありますが、取得できないものもあります。アンケートデータと比較すると、口コミデータは取得できる属性情報が限られており、またコメントの内容も丁寧に書かれているものもありますが、雑なものや、酷い言葉が使われているもの、正しい文法で書かれていないものもあるなど、データの質の面では口コミデータはアンケートデータよりも劣るかもしれません。しかし、データの量の面ではとても多くのデータを得ることができます。また、自社の商品だけでなく、他社の商品に対する評価についてもデータを得ることができるため、自社に限らない業界全体における消費者の評価の傾向を把握できます。企業でもこうした口コミデータを収集し、自社商品の改善やマーケティング、競合他社の分析などに活用する試みがされています。なお、口コミデータはWeb上で誰でも閲覧できますが、そのデータの取得と利用に関してはルールが設定されていることがあるため、利用を検討する際には必ずそのWebサイトの利用規約を確認することが必要です。
口コミデータを分析する場合、従来は、集計しやすい評点だけを集計したり、口コミのコメントは目視で1件1件確認したり、あるいはテキストマイニングでコメントの全体像を単語ベースに可視化して把握するといったことは実施されています。そこにトピックモデルとベイジアンネットワークを適用することで、コメントから抽出されたトピックと、口コミの評点や投稿者の属性情報などの因果構造をモデル化できます。
たとえば、口コミ評点に対する投稿者の性別や年代、商品属性、口コミトピックの関係をモデル化できます。こうしたモデルを用いることで、消費者の属性や商品の属性、さらにはコメントのトピックから評点に影響を与える要因を把握できます。また、ベイジアンネットワークで構築された確率モデルを利用することによって、各要因の条件から評点の確率分布を推論したり、評点を高めるには各要因をどのような状態にすればよいのかという推論をすることもできます。つまり、どのような属性の人がどのような属性の商品にどのようなコメントをすると、評価にどの程度影響するのかということを定量的に把握できます。こうした結果から、満足度を向上させるためには、属性別にどのような商品・サービスが提供されることが望ましいのかといった、マーケティング戦略などへの活用が考えられます。
また、口コミのトピックに対する因果構造をモデル化することもできます。こうしたモデルを用いることで、たとえば消費者の属性と商品の属性によって、口コミのコメント内容がどのように変化するのかということを把握できます。そしてベイジアンネットワークの確率モデルを利用することによって、商品の属性と顧客の属性を条件として入力すれば、どのようなコメントを発する傾向にあるのか、すなわち商品のどのようなことに関心が強いのかということを把握できます。これによって、それぞれの属性条件の関心対象に応じた商品企画をするといった活用が考えられます。
コールセンターの問い合わせ履歴データの分析
企業のコールセンター窓口に連絡のあった問い合わせ情報は、オペレータがその内容を文章で記録していることが多く、最近では音声から直接テキストに変換されるシステムを導入している企業もあります。問い合わせデータの記録対象は企業によってさまざまですが、その問い合わせが企業のどの商品・サービスに対するものなのかに紐づいて記録されていることも多いです。情報が取得可能な場合は、問い合わせをした顧客の属性情報も紐づけられていることもあります。また、問い合わせ内容によってエスカレーション(オペレータがその場での対応が困難な問い合わせに対して、専任者に引き継ぎをすること)の発生有無が記録されていたり、問い合わせが苦情の場合はその不満度がオペレータの主観で点数付けがされることもあります。他に、契約商品の解約要求や会員の退会要求といった、問い合わせに関する顧客の要求行動の情報が付与されることもあります。
企業のコールセンター部門では、顧客の問い合わせに対応することがメインの業務であり、その問い合わせ内容と対応の履歴をデータとして記録するのは、あくまでも顧客対応のためです。つまり、そのデータを分析し他の業務に活用することを主目的にしたものではないですが、ここで記録・蓄積されているデータは、顧客の生の声による潜在的なニーズが詰まった貴重なデータです。こうした顧客の問い合わせデータを分析して他の事業部門が活用することは、より顧客目線でビジネスを展開する上でとても価値があるといえます。実際にコールセンターの問い合わせデータの分析は、企業がテキストマイニングを実施する際によくあるテーマですが、やはりテキストマイニングのツールを使って、従来の単語ベースの可視化に留まるケースが多いです。しかし、コールセンターの問い合わせデータは、企業の規模によっては年間数十万件、数百万件というデータが蓄積されており、企業のテキストマイニングのテーマの中では、トップクラスのビッグデータです。
単語ベースの可視化をして全体像を把握する従来のテキストマイニングでは、その対象がビッグデータだとマイニングで抽出される単語も膨大になるため、結果はとても複雑化し解釈困難なアウトプットになってしまいます。こうした大規模なテキストデータの分析には特にトピックモデルの適用が有効となります。大量に抽出される単語をいくつかのトピックに変換することで、従来の単語ベースではなく、トピックベースで特徴の全体像をシンプルにわかりやすく解釈できます。さらにそこにベイジアンネットワークを適用すれば、顧客の問い合わせ内容に関連した要因関係を構造的にモデル化でき、顧客ニーズのより深い洞察を定量的に得ることができます。
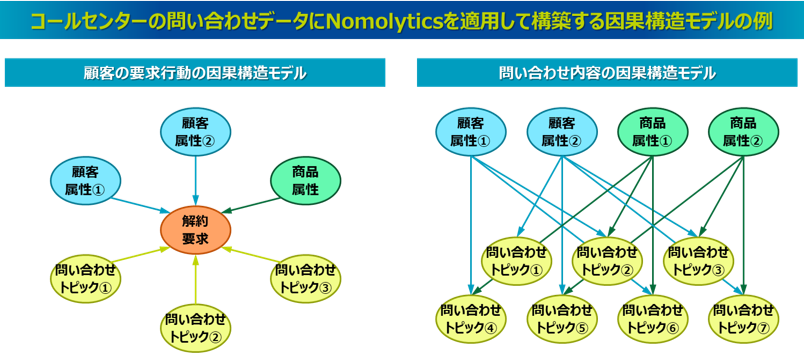
ここではコールセンターの問い合わせデータにNomolyticsを適用して因果構造モデルを構築するアプローチの例を紹介しますが、基本的には先述したアンケートデータのモデル化や口コミデータのモデル化と同様です。たとえば、各問い合わせデータに対してエスカレーションの発生や不満度といった問い合わせの状態に関する情報、契約の解約要求や会員の退会要求といった顧客の要求行動に関する情報などがあれば、その結果に対して顧客属性や商品属性、問い合わせ内容のトピックといった要因の関係構造をベイジアンネットワークでモデル化します。こうしたモデルを用いることで、どのような属性の顧客がどのような属性の商品にどのような問い合わせをすると解約につながるのか、あるいはエスカレーションのような対応困難となるのか、あるいは不満度が高まるのかといった、各要因との関係性を把握できます。そしてベイジアンネットワークで構築された確率モデルを利用することで、こうした要因から解約確率を推論したり、その解約確率を減少させるためにどのような内容の問い合わせを解消すべきなのかということも推論できるため、顧客の離反防止策の検討などへの活用が考えられます。
また、先ほどのアンケートデータや口コミデータと同様に、問い合わせのトピックに対する顧客属性や商品属性の因果構造をモデル化することもできます。こうしたモデルを用いることで、どのような属性の顧客はどのような商品でどのような問い合わせをする傾向にあるのか、その確率をシミュレーションできます。この結果を用いることで、既存商品の改善に活用することができます。また、新規商品を市場に投入する際には、その商品の属性からどのような問い合わせが発生する可能性が高いのか事前に予測することもできるため、問い合わせ対応の事前準備などにも活用が考えられます。