PCSA(確率的因果意味解析)
PCSAの概要
PCSAとは、Probabilistic Causal Semantic Analysis(確率的因果意味解析)の略で、テキストデータの分析において特徴を見たいターゲットを定め、そのターゲットに影響を与えるような要因的なトピックを優先して抽出する技術です(特許登録済:特許第7221526号)。PCSAはPLSAを応用して開発したトピック抽出の技術ですが、通常のPLSAがテキストデータ全体を表すような平均的で代表的なトピックを抽出する手法であるのに対し、PCSAでは探索したいターゲットの特徴を左右するような要因的なトピックを優先して抽出します。
ターゲットの要因を探索する意義とPCSAの開発背景
ビジネスの課題解決において有効なアクションを検討するためには、その課題となるターゲットに対して要因を探ることはとても重要です。たとえば、商品の顧客満足度の要因を探ることで、満足度の高い新商品の企画や現商品のプロモーションを検討できます。あるいは、サービスの解約や会員の退会などの要因を探ることで、顧客を維持する対応やサービスの内容を検討できます。
データ分析において、こうしたターゲットの要因を探るアプローチは、回帰分析や決定木分析など、しばしば教師あり学習の手法が適用されます。つまり、ターゲットとなる目的変数とその要因となる説明変数との関係をモデル化するアプローチです。また、説明変数の候補が多量となる高次元のデータでは、教師なし学習と教師あり学習を組み合わせるアプローチがよく適用されます。多量な変数をいくつかの特徴に教師なし学習で次元圧縮し、その集約された特徴を説明変数として設定し、目的変数との関係を教師あり学習でモデル化するというアプローチです。従来よく用いられてきたものとして、まず主成分分析や因子分析を実行し、その因子を説明変数に回帰分析を実行するアプローチがあります。たとえば、アンケートの多量な設問項目を因子分析でいくつかの因子にまとめ、その因子と顧客満足度などのターゲット設問との関係を回帰分析することで、顧客の価値観を理解し、マーケティングの検討に適用されるケースが挙げられます。
当社の代表技術のNomolyticsも、教師なし学習と教師あり学習を組み合わせたテキストデータの分析手法と解釈できます。Nomolyticsでは、テキストマイニングで抽出された単語群に教師なし学習のPLSAを適用してトピックを抽出し、そのトピックを確率変数として教師あり学習のベイジアンネットワークを適用してモデルを構築しています。たとえば、アンケートデータへの適用では、顧客満足度やロイヤリティの要因となる自由記述トピックを探ったり、口コミデータへの適用では、口コミ評点の要因となる口コミトピックを探ったり、コールセンターの問い合わせデータへの適用では、解約や退会の要因となる問い合わせトピックを探るモデルを構築できます。また、特許文書データの分析では、技術の要因となる用途、あるいは用途の要因となる技術を探るモデルを構築できます。
このように教師なし学習と教師あり学習を組み合わせることで、多量の変数を持つ高次元なビッグデータでも、次元圧縮された特徴量の変数を使って、ターゲット変数との関係をシンプルに理解することができます。しかし、こうしたアプローチでは教師なし学習と教師あり学習はそれぞれ独立しています。つまり、まず教師なし学習を完了してからその結果を教師あり学習に引き継ぐもので、それはNomolyticsも同様です。そのため、教師なし学習で抽出された特徴量は、どれもターゲット変数と強い関係を示すとは限りません。教師あり学習のモデリングの過程で、ターゲット変数に有効な特徴量のみが選択されることになります。一方、ビジネスの課題解決の場面では、初めからターゲットに影響を与える要因に特化して特徴量が抽出される方が、効率的で望ましいとされることもあります。
そこで課題となるターゲットを設定したときに、テキストデータからそのターゲットに影響を与えるトピックを優先的に抽出する手法としてPCSAを開発しました。
PCSAの技術的解説
通常のPLSA
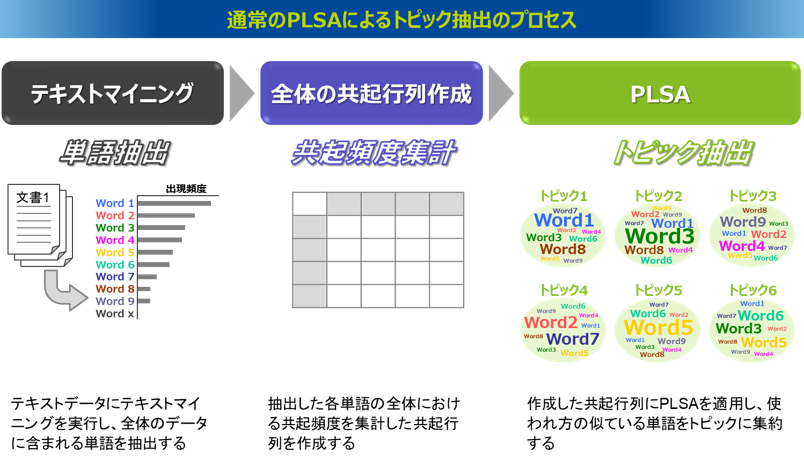
PCSAはPLSAを応用したトピック抽出手法です。PLSAによるトピック抽出のプロセスをおさらいすると、まずテキストデータにテキストマイニングを実行して単語を抽出し、その単語群の共起頻度を集計した共起行列を作成します。そしてこの共起行列をインプットとしてPLSAを適用することで、使われ方の似ている単語でまとめられたトピックを抽出します。この共起行列は全体のテキストデータから作成するため、当然そこから抽出されるトピックは全体を表現するような平均的で代表的なトピックが構成されることになります。
PCSAの考え方
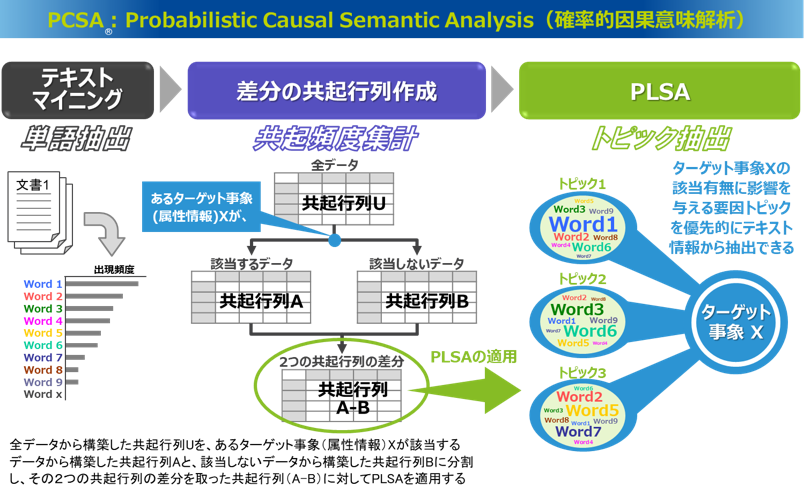
PLSAに対してPCSAでは、まず特徴を見たいターゲット変数を設定します。たとえば、アンケートデータでは顧客満足度、口コミデータであれば口コミ評点、コールセンターの問い合わせデータでは解約希望の有無といった変数が考えられます。特許文書のデータでは、最近トレンドを形成している技術を見たければターゲット変数は出願年が候補となり、引用の多い技術を見たければターゲット変数は引用数という情報が候補となります。PCSAでは、このターゲット変数を該当有無(1, 0)で示される二値変数に変換したものを使用します。
PLSAでは共起行列をすべてのデータから1つ構築していましたが、PCSAでは、設定したターゲット変数が「該当するデータ」と「該当しないデータ」、それぞれから同じ行列構成の共起行列を作成します。そして、この2つの共起行列の差分(差の絶対値)を計算した共起行列を作成し、これをインプットにPLSAを適用するというものです。
なお、全データをターゲット変数に該当するデータと該当しないデータの2つのグループに分割した際、それぞれのデータ件数の規模には違いがあるため、PCSAで適用する差分の共起行列は、そのデータ件数の規模の違いを考慮して調整を施して差分を取ります。具体的には、件数の少ないグループのデータ件数を基準に、件数の多い方のグループの共起行列の頻度をデータ件数の比率で調整します。データ件数が多い方のグループを調整対象とする理由は、その逆で調整した場合、たまたま共起したような小さな頻度が、調整によって実際には起こりえないような大きな値になってしまう可能性があるためです。共起行列では頻度1件の共起ペアは非常に多いですが、これはたまたま1件出現したというケースもあり、これがすべて同じ割合で増加することの影響は大きく、現実と乖離した頻度になってしまう懸念があります。一方、件数の少ない方のグループの頻度に合わせれば、件数の多い方のグループの頻度が調整されて値が小さくなりますが、調整後の頻度が0件(存在しない)になることはないので、件数の少ない方のグループの頻度を大きくすることよりも現実的と考えられます。
PCSAの効果
このようにターゲット変数の該当有無にしたがって2つのデータに分割し、それぞれ同じ行列構成で作成された共起行列は、ターゲット変数の該当有無に影響を受ける共起ペアでは頻度の差が大きくなり、その影響を受けないような共起ペアでは頻度の差は大きく生じないことになります。つまり、2つの共起行列の差分を取った共起行列では、ターゲット変数の該当有無に影響を受ける共起ペアは頻度が大きくなり、そうでない共起ペアでは頻度が小さくなるということです。そのため、この共起行列にPLSAを適用することで、ターゲット変数の該当有無に影響を与えるような要因トピックが優先的に抽出されることが期待できます。
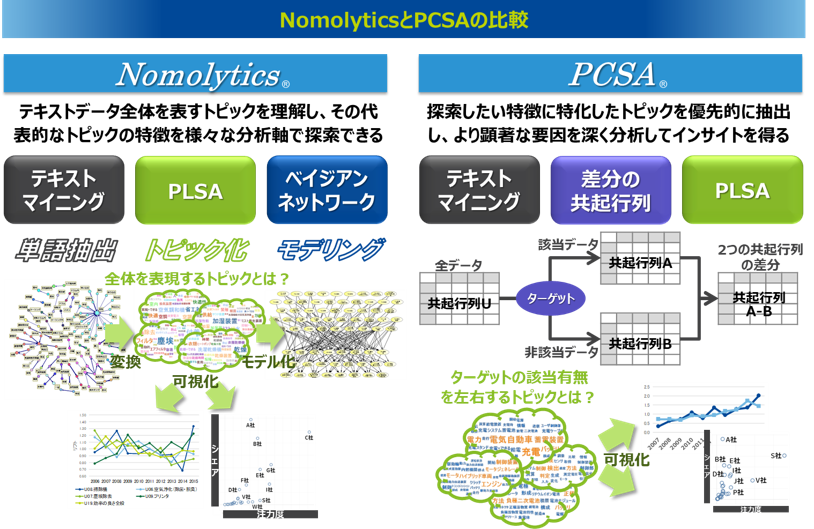
NomolyticsとPCSAの比較
Nomolyticsでは、まずテキストデータ全体を表現するような平均的で代表的なトピックを抽出し、そのトピックの特徴を様々な分析軸で探索します。分析軸とは、たとえば、アンケートデータであれば回答者の属性や顧客満足度などを含む他の設問回答結果、口コミデータであれば投稿者の属性や口コミ評点、コールセンターの問い合わせデータであれば顧客の属性や製品の属性、特許文書データであれば特許の出願年や出願人などが該当します。
PCSAでは、特徴を探索したいターゲットが定まっているときに適用するもので、そのターゲットの特徴に特化したトピックを優先的に抽出します。このトピックはデータ全体を表現する平均的で代表的なものではなく、その特徴をよく表現するようないわば偏ったトピックを抽出します。たとえば、アンケートデータの顧客満足度を高める自由記述トピックを抽出したり、口コミデータの評点を高める口コミトピックを抽出したり、コールセンターの問い合わせで解約・退会を増加させる問い合わせトピックを抽出したり、特許文書データで最近トレンドを形成している技術トピックを抽出するということが可能になります。PCSAによってターゲットに特化して抽出されたトピックを使うことで、探索したい特徴がより顕著に現れる要因を深く分析することができ、全体の平均的で代表的なトピックでは見えてこなかったインサイトの獲得が期待できます。
なお、NomolyticsとPCSAでどちらが優れているということはなく、目的に応じて使いこなすことが重要です。たとえば、PCSAは分析軸を最初から一つに絞り、それに特化したトピックを抽出できますが、Nomolyticsのようにさまざまな分析軸で広く特徴を探索したいというときには不向きになります。PCSAは、ビジネスの課題解決において、特定された課題の要因を探り、深いインサイトを獲得したい場合において有効になる手法ですが、インプットとなる共起行列は加工を施しているため、そこで抽出されるトピックはデータ全体を表現するものではなくなっています。データ分析の取り組みでは、まずは全体像を把握することが第一となるので、データ全体を表現するようなトピックを把握し、全体像を俯瞰したいときには、Nomolyticsを適用する方が適していることになります。したがって、繰り返しになりますが、目的に応じた手法の使い分けが重要になります。