大規模言語モデル
大規模言語モデル(Large Language Model, LLM)とは、Transformerというアーキテクチャを基盤とする深層学習モデルです。膨大なテキストデータの自己教師あり学習によって大量の穴埋め問題を解き、文脈を捉えた汎用的な言語特徴を事前学習したモデルとなります。これは第3次AIブーム後半の自然言語処理技術を象徴する存在であり、2017年に発表されたTransformerが大きなブレイクスルーとなりました。
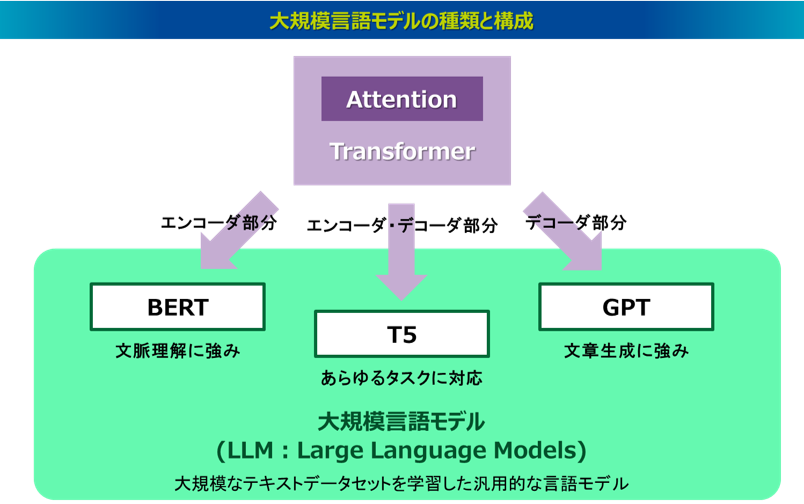
ここでは、大規模言語モデルの基盤構造となる「Transformer」と、その構造を基に発展した代表的な大規模言語モデルである「BERT」「GPT」「T5」を取り上げ、それぞれの概要を解説します。さらに、その先端の自然言語処理技術である大規模言語モデルと、従来からテキストデータの分析で広く活用されてきたテキストマイニングとの特徴や用途を比較し、その違いも整理します。
Transformer
Transformerは、2017年にNeurIPS(Neural Information Processing Systems)というAI 分野のトップカンファレンスで、"Attention is All You Need"というタイトルでGoogleとトロント大学の研究者によって発表された手法です24)。タイトルのとおり、Transformerは、Attentionだけを用いた(正確にはAttentionを中心に設計された)エンコーダ-デコーダ構造の深層学習アーキテクチャであり、従来主流であったRNNやCNNの仕組みを使わないアプローチとして提案されました。従来のseq2seqはRNNやLSTMを連結した構造となり、一つひとつ単語を入力して処理をするという逐次的処理で並列化計算が難しかったのですが、Transformerは一度に複数の単語を入力して並列化処理が可能になり、学習にかかる時間を大幅に短縮させることができました。高精度でかつ計算効率が非常に高いTransformerは、第3次AIブームの自然言語処理技術において大きなブレイクスルーとなりました。非常に大規模なデータの学習も可能となったため、後に提案されるBERT、GPT、T5といった汎用大規模言語モデルは、その中核技術としてTransformerが用いられました。なお、ここではTransformerの構造を分かりやすく理解するための解説に留め、詳細な解説はTransformerの論文や他の専門書に委ねます。また、大規模言語モデルの開発が活況となっている昨今では、Transformerの改良アプローチも数多く提案されていますが、ここでは2017年に発表された初期のTransformerを対象に解説しています。
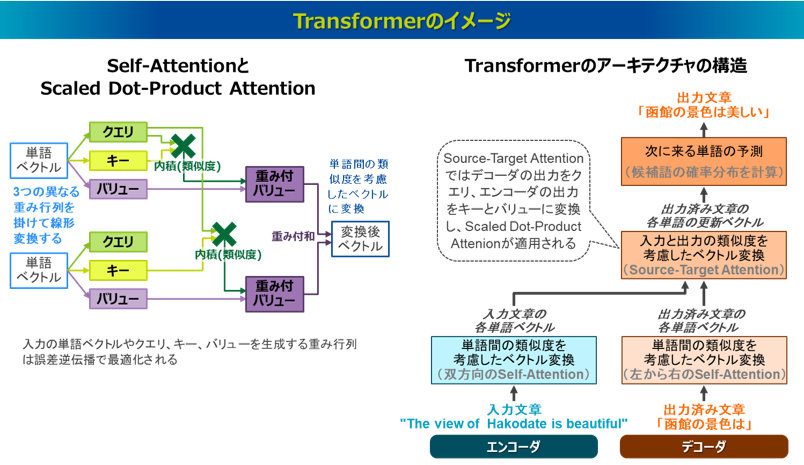
Transformerが高い精度と高い計算効率を実現している原理を理解する上で、そのアーキテクチャの構造において、特に3種類のAttentionの仕組みが中心的な役割を果たしているとされています21)。これらの処理により表現力の高いベクトルを獲得しながら、内積ベースの行列演算によって高速な並列計算が可能になりました。以下にその3種類のAttentionの仕組みの概要を解説します。
一つ目はSelf-Attentionという仕組みです。元々のAttentionは、入力文章(Source)の単語と出力文章(Target)の単語を対応づけたSource-Target型のAttentionでしたが、Self-Attentionは、入力文章と出力文章のペアではなく、同一文章の中の各単語が他の単語とどの程度関係しているのかを評価します。これにより、単語間の依存関係を学習することができ、より表現力の高いベクトルを獲得することができます。なお、Transformerの処理単位は正確には単語ではなくトークンという文字列の固まりですが、ここでは分かりやすく処理単位を単語として解説していきます。
二つ目はScaled Dot-Product Attentionという仕組みです。これはSelf-Attentionにおいて、単語間の内積の類似度計算により他の単語との関連性を考慮した単語ベクトルを獲得する仕組みです。具体的な処理としては、各単語を固有の埋め込みベクトルに変換し、この単語ベクトルに対して、3つの異なる重み行列を掛けて線形変換を施した、「クエリ」「キー」「バリュー」という3つのベクトルを作成します。「クエリ」は「この単語はこういう情報が欲しい」ということを表すベクトル、「キー」は「この単語はこういう情報を持っている」ということを表すベクトル、「バリュー」は「だからこういう情報を渡す」ということを表すベクトルとなっています。まず、各単語のクエリに対して文中の他のすべての単語のキーとの類似度を、それぞれのベクトルの内積によって計算します。この内積は欲しい情報と持っている情報のマッチ度を意味します。このとき、ベクトルの次元数が大きいと内積の値が大きくなりすぎるため、実際はその内積を次元数の平方根で割ってスケーリングします。そしてすべての単語に対して計算したスケーリング済みの内積にsoftmax関数を適用することで、合計が1となるように調整され、これがAttentionの重みとなります。この重みを各単語のバリューに掛け、それらすべてのバリューの重み付き和を取ったベクトルを元々の単語の新たな表現ベクトルとして生成します。これはクエリとキーのマッチ度が高いほどバリューで渡す情報が強くなることを意味します。つまり、それぞれの単語は文中の他の単語との類似度を反映したベクトルに変換されるということです。このように一つの単語に対して「クエリ」「キー」「バリュー」という役割の異なる3つのベクトルを設定して単語同士の関係性を学習することで、とても高度な表現力を獲得できるようになります。各単語の埋め込みベクトルや各重み行列などのパラメータは、モデルの学習過程で誤差逆伝播法によって、予測単語と正解単語の差異を最小にするように最適化されます。なお、各単語の埋め込みベクトルは単語によって異なりますが、クエリ・キー・バリューを作成する3つの重み行列は全ての単語で共通したものを学習します。
三つ目の重要なAttentionの仕組みはMulti-Head Attentionというもので、これはSelf-Attentionを異なる表現空間(ヘッド)で複数パターン実行し、より柔軟な単語ベクトルを獲得するというものです。先述したScaled Dot-Product Attentionの説明では、1つの単語ベクトルに対して3つ1セットの重み行列を掛けて線形変換することで、クエリ・キー・バリューのベクトルを作成していました。一方、Multi-Head Attentionでは、設定したヘッドの数だけこの処理を異なる重み行列で実行するイメージです。つまり、1つの単語ベクトルに対してヘッド毎に異なるセットの重み行列を掛けることで、複数パターンのクエリ・キー・バリューのベクトルを作成します。そうしてヘッドの数だけ得られた複数の出力ベクトルを統合して、最終的に1つのベクトルに落とし込みます。これにより複数の異なる観点からの類似度が考慮され、モデルの表現力を大きく向上させることができます。なお、各ヘッドの重み行列の次元数は、元の次元数からヘッドの数で分割した次元数となっており、最終的に各ヘッドの出力ベクトルを並べて結合することで、再び元の次元数のベクトルになります。
Transformerのアーキテクチャを簡略化すると、(1)エンコーダと(2)デコーダの2つの処理プロセスに分けられ、デコーダのプロセスはさらに3つのステップに分けると分かりやすいです。それは、(2-1)出力済みの文章の単語をベクトル化するステップ、(2-2)入力文章と出力済み文章の類似度に基づいて出力済み文章の単語のベクトルを更新するステップ、(2-3)次にくる単語を出力するステップです。これらは以下のイメージ図(右側)の各処理ブロックに該当します。特にTransformerの特徴を示すステップが(1)(2-1)(2-2)といえます。まず(1)エンコーダの処理プロセスでは、先述の3種のAttentionにより、入力文章に存在するそれぞれの単語のベクトルをより表現力の高いベクトルに変換します。
次はデコーダの処理プロセスに移ります。まず、(2-1)出力済みの文章のそれぞれの単語をベクトル化するステップでは、エンコーダの処理と同様に、途中まで出力された文章において3種のAttentionが適用され、出力済みの文章に存在するそれぞれの単語においてより表現力の高いベクトルが得られます。ただし、エンコーダのSelf-Attentionと違い、デコーダではまだ出力されていない未来の単語は参照できないというルールがあり、双方向に参照ができるエンコーダに対して、デコーダでは自身の単語よりも左側ある単語しか参照できません。
次に(2-2)入力文章と出力済みの文章の類似度に基づいて出力済み文章の単語のベクトルを更新するステップでは、入力文章の各単語と出力済みの文章の各単語の類似度を考慮したAttentionが適用されます。このAttentionは従来のseq2seqで適用されたSource-Target型のAttentionのアプローチが採用されます。このAttentionは、Encoder-Decoder AttentionやCross-Attentionとも呼ばれますが、ここでもクエリ・キー・バリューの3つのベクトルが用いられます。具体的には、デコーダで出力済みの文章(ターゲット文章)において出力された各単語ベクトルをクエリとし、エンコーダの入力文章(ソース文章)において出力された各単語ベクトルをキーとバリューとし、この3つのベクトルを使ってScaled Dot-Product Attentionの処理を行います。これによりデコーダの出力済み文章の各単語に対して、入力と出力の類似度に基づいた新たな表現ベクトルが得られます。なお、(1)のエンコーダと(2-2)のデコーダで得られる各単語の表現ベクトルは、FFN(Feed-Forward Network)という2層の全結合ニューラルネットワークを通過します。これは得られた表現ベクトルに対して、1層目で次元数を拡大した重み行列を掛けた線形変換した後にReLU関数などの活性化関数で非線形変換をし、2層目で元の次元数の重み行列を掛けた線形変換をすることで、元の次元数のベクトルに戻します。こうした非線形変換と次元の拡大・縮小により、線形的な情報だけでなく、非線形的な複雑な情報を含む表現力の高いベクトルを獲得しています。また、エンコーダの(1)とデコーダの(2-1)(2-2)は、実際には何層にも積み重ねて計算されます。つまりそれぞれの一連の計算過程を、重みを変えながら何度も繰り返していくことで、より洗練された表現ベクトルを獲得します。
最後に(2-3)次にくる単語を出力するステップでは、(2-2)で更新されたベクトルに基づいて、次にくる単語が予測されます。つまり、単語の予測には出力済みのすべての単語の情報に加え、入力文との依存関係の情報が利用されていることになります。具体的な予測の処理は、デコーダで更新された出力済みの単語の新たな表現ベクトルに対して、候補となる単語群(語彙)の重み行列を掛けた線形変換を施すことで、その候補単語のスコアが計算されます。そして、それをsoftmax関数で確率分布に変換し、最も確率の高い単語が選ばれます。ここで、次にくる単語を予測するときに使われるのはその直前の単語、つまり出力済みの単語のうち右端にある最後の単語のベクトルになりますが、この最後の単語にはこれまで出力された全ての単語の文脈情報が凝縮されていることになります。なお、デコーダでまだ何も出力されていない最初の状態では、これから出力を開始する合図となる特別な開始トークン(たとえば<SOS>や<start>など)がデコーダに入力され、その開始トークンがエンコーダからの出力(各単語の表現ベクトル)を受け継ぎ、次の単語(実質的には最初の単語)を予測することになります。
Transformerのモデルを学習するときは、この予測単語と正解単語の一致度を損失関数とした誤差逆伝播法により、モデル全体の各パラメータ(単語の埋め込みベクトルや各重み行列など)が最適に更新されます。ここで特に規模が大きくなるパラメータはSelf-Attentionの重み行列とFFNの2層の重み行列になります。学習済みのTransformerのモデルを推論に使うときは、これらのパラメータを固定して適用することで推論を実現します。なお、Transformerは先述したエンコーダとデコーダのプロセスのように、逐次的に単語を生成して都度計算しているように見えますが、モデルの学習時では、各パラメータは内積をベースにした行列演算で一気に並列計算していきます。一方、学習済みのモデルを推論に使用するときは、逐次的に単語を生成していきます。
また、Transformerは従来のRNN構造を持たないため、Attentionだけでは単語の順序情報を学習することができません。そこでTransformerはPositional Encodingと呼ばれる手法で、単語の埋め込みベクトルに順序情報を加えています。具体的には周期性のあるsin関数とcos関数を使って何番目にある単語なのかという情報を含む位置情報ベクトルが生成され、それが最初の段階で各単語の埋込みベクトルに加算されます。順序情報を単純な1,2,3,4といった連番ではなく、sin関数とcos関数を使用するメリットは、周期性がある関数によりシーケンスの長さに影響を受けないで順序情報を与えることができることが挙げられます。また、各単語間の相対的な距離や位置がすべて同じではなくそれぞれ区別された異なる数値によって表現されるため、単語間の複雑で微妙な位置関係もより豊かに捉えることができるというメリットも挙げられます。なお、この位置情報ベクトルは学習過程で最適化されるパラメータの対象ではありませんが、これは初期のTransformerの方法で、学習から取得するアプローチも後に提案されています。
Transformer はもともと機械翻訳タスク向けに開発されたモデルでしたが、多くの自然言語処理タスクで応用が可能であり、どのケースでも非常に高い性能を実現しました。また、自然言語処理の分野を超えて、Transformerは画像認識や画像生成の分野でも応用されています20)。たとえば2020年にGoogleによって発表され、画像認識にTransformerを用いたViT(Vision Transformer)や25)、2021年にOpenAIによって発表され、画像生成にTransformerを用いたDALL-Eがあります26)。このようにTransformerは多様な分野に応用されるほど、その情報処理能力の高さは驚異的でした。
BERT
BERT(Bidirectional Encoder Representations from Transformers)は、Transformerを使って大量のテキストデータを事前学習した汎用的な大規模言語モデルです。2018年10月にGoogleによってプレプリントという形で発表され27)、その後2019 年6 月に開催されたNAACL(North American Chapter of the Association for Computational Linguistics)という自然言語処理分野のトップカンファレンスで発表されました28)。2019年10月にはGoogleが検索エンジンにBERTを採用し、「過去5 年間で最大の飛躍」と発表され話題となりました。今まで検索キーワードに対して検索結果を返していたところを、文章の検索に対して結果を返せる精度を大幅に向上させました。
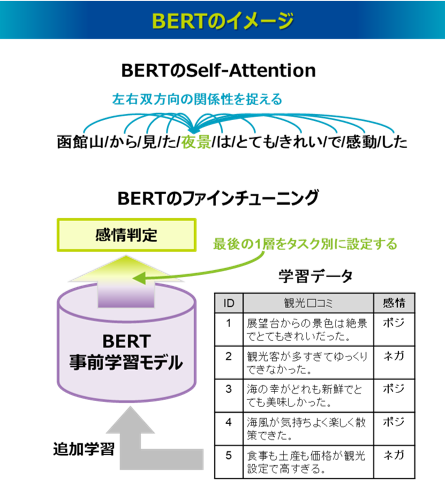
BERTは、Transformerのエンコーダ部分を使用したモデルであり、BERTの頭文字であるBidirectional(双方向)の意味は、Self-Attentionを実行するときに、各単語は同一文中の左右にある他のすべての単語との関係性を捉えるということです。ただ、これは通常のSelf-Attentionの仕組みと同じです。BERTがわざわざ双方向を強調したのは、BERTより先の2018年6月にOpenAIによって発表されたGPTと明確に区別する意図があるともいわれています21)。GPTについては次に解説しますが、GPTはTransformerのデコーダ部分を使用したモデルであり、左から右の一方向のSelf-Attentionが実行され、文章生成などのタスクを得意としています。これに対してBERTはその双方向のSelf-Attentionにより、文章全体の文脈理解において優れており、文章分類や感情分析などのタスクに適しているといわれています。
BERTの事前学習では、自己教師あり学習のMLM(Masked Language Model)とNSP(Next Sentence Prediction)が実行されます。MLMは、文中の一部の単語をマスクし、その単語を双方向から予測するタスクです。この穴埋め問題の予測はSelf-Attentionによって得られる各単語の表現ベクトルを入力とした深層学習モデルが適用され、誤差逆伝播法によってSelf-Attentionにおける各重み行列が最適に更新されます。これにより各単語が文中でどのように使われているのかという理解を深め、文脈を捉えた単語の表現を学習できます。MLMが単語単位の学習であるのに対し、NSPは、文単位の学習となります。NSPでは2つの文が与えられたときに、それらが連続する文か否かを予測します。これにより文の流れや論理的なつながりを理解し、文章全体の構造を把握する能力を向上させます。BERTはこうした事前学習を通じて広範な文脈理解能力を獲得しています。なお、BERTでは、入力文章の先頭には[CLS]という特殊なトークンが挿入され、このCLSトークンも他の単語と同様にSelf-Attentionでベクトル表現が学習されますが、CLSトークンは文章全体の意味を表すような表現となります。NSPの事前学習では、2文を連結した先頭に挿入されたCLSトークンに対応するベクトルを用いて、それらが連続するか否かを判定しています。
このようにBERTでは、文章全体の文脈を捉えた単語のベクトル表現を、あるいはCLSトークンに対応する文章のベクトル表現を出力することができます。たとえば従来のword2vecも単語のベクトル表現を出力できますが、word2vecは同じ単語は同じベクトルが付与されます。「マウスをクリックする」と「マウスで実験する」で登場する「マウス」はword2vecでは同じベクトル表現となりますが、BERTでは文脈を考慮した異なるベクトル表現として得られます。
なお、BERTには代表的なモデルにBaseモデルとLargeモデルがあります。BaseモデルはTransformerのエンコーダ層を12層重ねており、パラメータ数は1.1億個で768次元のベクトルを出力します。LargeモデルはTransformerのエンコーダ層を24層重ねており、パラメータ数は3.4億個で1024次元のベクトルを出力します。
また、BERTの事前学習モデルを再利用し、個別のタスクに応じた比較的小規模な教師データで追加学習をするファインチューニング(Fine-tuning)を施すことで、その個別タスクに応じてモデルが微調整されます。これによって、少量の学習データでも高い精度を得ることができます。その仕組みは、文章分類や感情分析、質問応答といった個別のタスクに対して、BERTの最後の1層だけそのタスクに特化したニューラルネットワークを追加します。つまりBERTで最終出力される単語や文章のベクトル表現を入力層とし、タスクの解答を示す出力層を追加したニューラルネットワークをBERTの最終層に構成します。そしてそのタスクの教師データでBERTモデル全体を再学習させれば、そのタスクに最適なモデルを構築できるというものです。従来のように個別のタスクごとにモデルを構築しなくても、この事前学習モデル+ファインチューニングというアプローチにより、個別のタスクを低コストでかつ高い性能で実現できるということがBERTの大きな成果といえます。BERTが発表されて以降、自然言語処理領域ではとりあえずBERTを試してみるという取り組みが多発しました。
GPT
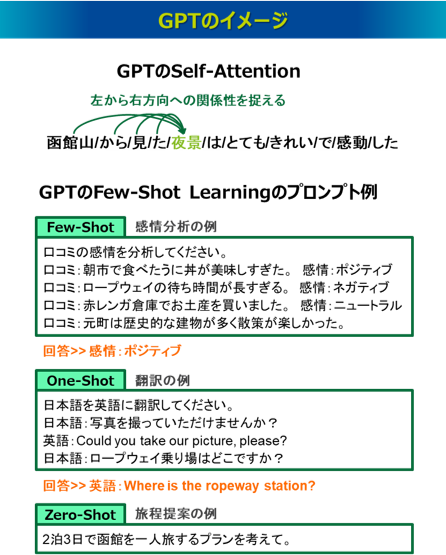
GPT(Generative Pre-trained Transformer)もTransformerを使って大量のテキストデータを事前学習した汎用的な大規模言語モデルであり、2018年6月にOpenAIによって発表されました29)。GPTは、Transformerのデコーダ部分を使用したモデルで、テキストの生成能力において優れており、文章生成や文章補完、要約作成、対話生成、言語翻訳などのタスクに適しているといわれます。GPTがSelf-Attentionを実行するときは、左側にある単語のみが使われ、一方向の関係性を捉えます。事前学習は自己教師あり学習となり、テキストの次にくる単語を予測し、これによりテキストの生成能力を獲得しています。
GPTの事前学習モデルを再利用する際は、特定のタスクの説明や指示を入力(プロンプト)として与えます。特にGPT-3からはFew-Shot Learningという概念が注目されました。これは入力に「ショット(shot)」と呼ばれるタスクを解く例(サンプル)を少数与えることで、ファインチューニングをすることなくさまざまなタスクに対応できるという、柔軟で効果的な学習能力です。与える例の数が少数(2個以上)ある場合をFew-Shot、1個ある場合をOne-Shot、タスクを解く例を一つも与えない場合をZero-Shotと呼びます。
なお、BERTのファインチューニングでは、特定のタスク用にモデル全体を再学習する手法であり、新しいタスク用の追加データセットを使用して、モデルの全パラメータを更新します。一方、GPTのFew-Shot Learningでは、新しいタスクを解決するための直接的なヒントやガイダンスを提供しているだけで、モデルのパラメータは固定され、更新されません。GPTがFew-Shot Learningにより新しいタスクに柔軟に適応できる理由は、その事前学習モデルが大規模なデータと大規模なモデル構造により学習されているためです。これにより言語パターンの高い汎用性と一般化能力を獲得し、少数の例からでもそのタスクの性質を理解し解決することを可能としています。ただし、さまざまなタスクに対応できる汎用性の高さがある反面、特定のタスクを対象に学習されたモデルと比べると性能が劣ることがあります。また、与えられるプロンプトの依存性が高く、これがモデルの性能に大きく影響を与えるため、ショットの内容を含む適切なプロンプトの設計が求められます。このようにモデルの性能を上げるような良いプロンプトを設計することをプロンプトエンジニアリングと呼び、さまざまなコツや例文が提案されています。
OpenAIは2019年にGPT-2を30)、2020年にGPT-3を発表し31)、2022年11月にはGPT-3.5をベースとしたチャットボット"ChatGPT"をリリースしました。ChatGPTの利用者数はリリース後2ヶ月で1億人に達し、その性能の高さに世界中が騒然としました。2023年3月にはさらに進化したGPT-4を公開し、2023年9月には音声や画像のデータもテキストのデータと同時に扱えるマルチモーダルなタスクに対応可能にしました。ChatGPTの発表を皮切りに生成AIブームが勃発し、巨大IT企業を中心に生成AIの研究開発と新たなサービスの競争が激化しました。
なお、初代GPTはTransformerのデコーダ層を12層重ねたモデルで、Book Corpusと呼ばれる未発表書籍7000冊分以上のテキストデータ4.5GBを学習し、モデルのパラメータ数は1.2億となっています。GPT-2はTransformerのデコーダ層を48層重ねたモデルで、40GBのWebテキストのデータを学習し、モデルのパラメータ数は15億となっています。GPT-3はTransformerのデコーダ層を96層重ねたモデルで、570GBのWebテキストのデータを学習し、パラメータ数は1750億個となっています。GPT3.5以降は、この記事を執筆した2025年4月時点では、モデルの内容の情報は公式に発表されていませんが、より大規模なデータでより大規模なパラメータ数の学習モデルが開発され続けています。
T5
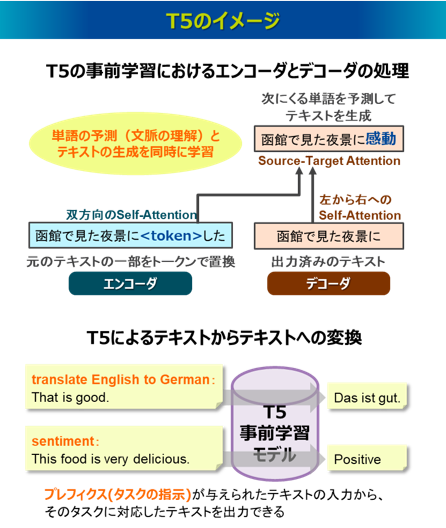
T5(Text-to-Text Transfer Transformer)もTransformerを使って大量のテキストデータを事前学習した汎用的な大規模言語モデルであり、2019年10月にGoogleによって発表されました32)。T5は、Transformerのエンコーダ-デコーダ構造を持つモデルで、従来のように個別タスクごとにモデルを構築するのではなく、”Text-to-Text”とあるように、あらゆる自然言語処理タスクをテキストからテキストに変換する同一のアーキテクチャで扱うことができます。たとえば、「翻訳:英語の文→日本語の文」、「要約:長い記事→短い要約」、「感情分析:口コミ→感情判定」など、タスクの詳細を入力テキスト自体に組み込むことで、あらゆるタスクを「入力テキスト→出力テキスト」という形式に統一します。これはBERTのように、事前学習+ファインチューニングというアプローチに基づき実現しています。
T5の事前学習も自己教師あり学習となりますが、エンコーダ-デコーダ構造の学習であることがポイントです。BERTとGPTの自己教師あり学習と比較すると、BERTはエンコーダモデルであり、テキストの一部をマスクし、それを双方向のSelf-Attentionで予測することで、高い文脈理解能力を獲得しました。GPTはデコーダモデルであり、左から右の一方向のSelf-Attentionによりテキストの次に来る単語を予測することで、高いテキスト生成能力を獲得しました。これに対してT5では、まずエンコーダにおいて、元のテキストの一部を特殊なトークンに置換します。より正確には、スパン(span)と呼ばれる単語あるいは連続する単語のフレーズをトークンで置換し、一部が欠落したテキストを用意します。そのテキストを対象に、エンコーダでは双方向のSelf-Attentionによってそのトークンも含めて各単語のベクトルを出力します。デコーダでは、すでに生成済みのテキストに対して、左から右への一方向のSelf-Attentionを適用し、生成済みのテキストに含まれる各単語のベクトルを出力します。さらに、エンコーダから受け取った各単語のベクトルに対してSource-Target型のattentionを適用します。これによりデコーダで生成済みのテキストに含まれる各単語は、エンコーダとデコーダの類似度に基づき新たな表現ベクトルを獲得します。そして、それらの表現ベクトルに対して、候補となる単語群(語彙)の重み行列を掛けた線形変換とsoftmax関数の確率分布の変換を施すことで、次にくる単語を予測しテキストを生成します。このプロセスによって結果的に特殊なトークンで置換された内容が復元され、それが正しい復元となるように各パラメータが最適化されます。つまり、T5の自己教師あり学習の狙いは、トークンで置換した欠落部分を単に予測するだけではなく、そのトークンを含むテキスト全体を生成してトークンの復元を実現することで、モデルに文脈理解能力とテキストの生成能力の両方を身につけさせることにあります。
この事前学習を大規模なデータセットと大規模なパラメータ数に基づいて実行することで高い汎化性能を得ています。なおT5の事前学習で用いられるデータセットは、Googleが作成した巨大データセットC4(Colossal Clean Crawled Corpus)というものであり、Webから収集されたデータにクリーニング処理をした745GBのデータセットです。モデルのパラメータ数に関しては、たとえばT5-Baseで2.2億、T5-11Bで110億となっています。
T5のファインチューニングでは、特定のタスク(翻訳、要約、分類、感情分析など)を指示するプレフィクス(prefix)というラベルを付けたデータを学習します。これにより、一つのモデルでさまざまなタスクに高い性能で対応することができます。たとえば英語をドイツ語に翻訳するタスクでは、プレフィクスとして” translate English to German: ”というラベルを与えます。つまり、T5のファインチューニングで追加学習するデータは、「translate English to German:英語文」の入力文章と「ドイツ語文」の出力文章のペアとなります。このファインチューニングにより、そのプレフィクスで指示されたタスクに対応したモデルに更新されます。
GPTでもFew-Shot Learningでさまざまなタスクに対応可能ですが、これはそのタスクの例やヒントを与えているだけで、モデル自体は更新されません。そのため、GPTは汎用性はありますが特定のタスクに特化したモデルとはならず、さらに良い例となるショットの提供を含む適切なプロンプトの設計も求められます。また、GPTでもテキストで入力したタスクに対してその回答がテキストで出力され、テキストからテキストに変換されるという形式でいえばT5と同様ですが、GPTはあくまでも入力したテキストの次にくる単語を予測しており、T5のように入力と出力の対応関係を強く捉えた生成ではないため、個別のタスクによっては性能が劣ることがあると言われていました。しかし、今のGPTの性能の前ではこうした評価はもはや意味がないかもしれません。
また、T5はさまざまなタスクに応じた柔軟で高い性能のテキスト生成ができるというメリットがある一方で、計算資源の要件にはハードルもあります。事前学習では膨大な計算資源が必要であり、ファインチューニングにおいても高い性能のモデルを実現するには比較的多くの計算資源が求められると言われています。
大規模言語モデルとテキストマイニング
ここまで解説したように、第3次AIブームは「Transformer」の登場により自然言語処理の分野で大きなブレイクスルーが起きました。そして、そのTransformerのアーキテクチャをベースに膨大なテキストデータを学習させた汎用的な大規模言語モデルとして、「BERT」「GPT」「T5」などが誕生しました。これらはテキストのデータを対象とした処理モデルですが、一方でテキストデータの分析と活用といえば、「テキストマイニング」が広く利用されてきました。テキストマイニングは、古典的な自然言語処理技術をベースにしたデータマイニングの手法ですが、大規模言語モデルが登場したからといってテキストマイニングが古臭い手法となるわけではありません。それは両者がどちらもテキストデータを扱う技術という点では共通していますが、その特徴や用途には大きな違いがあるためです。ここでは大規模言語モデルとテキストマイニングの位置づけについて、両者の特徴を対比しながら解説します。
大規模言語モデルの整理
まずは大規模言語モデルについてもう一度整理したいと思います。「BERT」「GPT」「T5」は、Attentionの仕組みだけを用いた「Transformer」というアーキテクチャに基づいて、大量のテキストデータから汎用的な言語特徴を学習した大規模言語モデルです。Transformerの構造のなかでも、BERTはエンコーダ、GPTはデコーダ、T5はエンコーダとデコーダを利用したモデルです。BERTは文脈理解に強みがあり、文章分類や感情分析などのタスクに適しているといわれます。GPTはテキスト生成に強みがあり、文章生成や文章補完、要約作成、対話生成、言語翻訳などのタスクに適しているといわれます。T5は文脈理解とテキスト生成の両方の能力を有していることで、あらゆるタスクに対応できる柔軟性があるといわれるが、比較的多くの計算資源が求められるといわれます。
2022年11月にOpenAIはGPTを利用したAIチャットボットサービス”ChatGPT”をリリースしましたが、これを機に世界中で生成AIブームが巻き起こり、大規模言語モデルのなかではGPTが主流となったといえます。
大規模言語モデルとテキストマイニングの比較
大規模言語モデルとテキストマイニングは、どちらもテキストデータを扱う手段という意味では共通しますが、それぞれの特徴や用途には大きな違いがあります。以下の表は観点別にその特徴の違いをまとめたものです。ただし、この表は大規模言語モデルとテキストマイニングを対比することで、その違いをわかりやすく理解することを目的にまとめたもので、タスクの条件や分析データの内容によって一概にはいえないため、あくまでも参考程度に捉えてください。以下にそれぞれの違いについて説明します。

まずは用途の違いについて確認すると、大規模言語モデルは大規模なテキストデータセットを事前学習した汎用的な言語モデルであり、その学習された言語の汎用的な特徴に基づいて、文章の文脈を評価したり、新しい文章を生成したりできます。これにより、文章分類や感情分析、文章や要約の作成、質問応答や対話生成、言語翻訳などを得意タスクとしています。一方、テキストマイニングは手元にある特定のテキストデータの個別の特徴を把握し、そこから有用なインサイトを得ることを目的とした手法です。特定のテキストデータに出現する単語を抽出し、その単語の頻度情報をベースとした集計や定量的な統計解析を実行します。
ビジネスの課題解決という命題の下では、大規模言語モデルは文章要約や言語翻訳など、そのアウトプットそのものが課題解決において直接的な価値を提供しているといえます。一方、テキストマイニングは、そのアウトプットは課題解決における意思決定に資する価値を提供するものであり、大規模言語モデルと対比すると、間接的なアプローチで課題解決に貢献していると捉えることができます。
それぞれのアウトプットが何に基づいて形成されるのかという点では、大規模言語モデルは事前学習した汎用的な言語モデルに基づいて推論された定性的な結果であるのに対し、テキストマイニングは特定のテキストデータの情報、とりわけ出現単語の頻度に基づいて可視化された定量的な結果です。つまり、大規模言語モデルは推論ベースに、テキストマイニングは事実ベース(形態素解析のルールベース)にアウトプットが形成されると捉えることもできます。たとえば大規模言語モデルを用いて文章分類や文章生成、言語翻訳などを行う場合、その結果は推論に基づくものであるため誤った結果となる可能性もあります。またChatGPTの利用においても、入力するプロンプトによって生成される結果は大きく影響を受け、同じプロンプトであっても異なる結果が生成されるなど、再現性が得られないこともあります。一方、テキストマイニングは特定のテキストデータにどの単語が何件出現するのかなど、そのデータの特徴をそのまま反映しており、結果は事実そのものです。正解や不正解といった概念はなく、当然同じ条件の分析において結果が変動することもありません。
次に、得意な処理と不得意な処理について確認しながらそれぞれの特徴を比較します。まずは大規模言語モデルが得意で、テキストマイニングが不得意な処理についてです。その代表として、大規模言語モデルは文脈を理解することが得意ですが、テキストマイニングは得意ではありません。たとえば「監督は選手にサインを送った」と「彼は契約書にサインした」という2つの文章で使われる「サイン」は同じ単語ですが、違う文脈で使用されています。テキストマイニングではどちらも同じ「サイン」として認識し、文脈による区別ができませんが、大規模言語モデルではこれらを違う文脈で登場する単語として認識できます。他を挙げると、テキストマイニングには文章のポジティブ・ネガティブを判定する感情分析を行う機能もありますが、これは固定化された語彙リストやルールに基づいて評価するものであり、文脈を捉えた評価になっていません。これに対して大規模言語モデルは文脈を理解した感情分析を実行することができます。こうした違いは、テキストマイニングでは特定の単語の出現有無をデータ処理の軸としている一方で、大規模言語モデルでは単語の順番や単語間の相互依存性といった文脈を考慮した単語の特徴ベクトルをデータ処理の軸としている違いで現れます。
逆に大規模言語モデルが不得意で、テキストマイニングが得意な処理もあります。たとえば、大規模言語モデルは大規模なテキストデータセットを事前学習した汎用性のある特徴を捉えたモデルですが、個別性の強い特徴を捉えることは得意とはいえません。これは過学習をしないように汎用的なモデルの学習を進めているため当然ですが、テキストマイニングでは手元にある特定のテキストデータを処理し、そのデータ特有の個別の特徴や傾向を可視化できます。また、大規模言語モデルのアウトプットは文章生成や質問応答など、その形式は定性的な情報ですが、テキストマイニングのように定量的な統計解析を正確に行うことは得意ではありません。他に、大規模言語モデルが不得意とする処理として、入力できるデータの規模があります。大規模言語モデルは事前学習時にはとてつもない規模のテキストデータを学習しますが、それを再利用するときに入力するテキストデータの規模は限定され、テキストマイニングのように大量のテキストデータセットを一気に処理することには向いていません。これは大規模言語モデルでは一度に処理できる単語数に制約があるためです。正確には単語ではなく、トークンと呼ばれる単位で処理をしていますが、大規模言語モデルでは計算コストの爆発抑制のため、このトークンの数に上限を設けています。たとえば、BERT の上限トークン数は512 個、GPT-3 の上限トークン数は4096 個でした。生成AIブームによって大規模言語モデルの開発の競争が激化する中で、この上限トークン数の拡大も進んでいますが、無制限ということはありません。
大規模言語モデルの開発が飛躍的に加速するなか、ここで挙げた大規模言語モデルの不得意な処理は克服される流れにありますが、技術の本質として大規模言語モデルとテキストマイニングにはどのような特徴がありどのような違いがあるのか理解することはとても重要で、課題に応じて手法を使い分けたり、組み合わせたりできることが人間の課題解決能力の本質といえます。
参考文献
24) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin: "Attention is All You Need," Proc. of the 30th International Conference on Neural Information Processing Systems (NeurlPS 2017), pp.6000–6010 (2017)
25) A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby: "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale," arXiv preprint arXiv:2010.11929 (2020)
26) A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever: "Zero-Shot Text-to-Image Generation," arXiv preprint arXiv:2102.12092 (2021)
27) J. Devlin, M. W. Chang, K. Lee, and K. Toutanova: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv preprint arXiv:1810.04805 (2018)
28) J. Devlin, M. W. Chang, K. Lee, and K. Toutanova: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," Proc. of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NCCAL-HLT 2019), Vol.1, pp.4171–4186 (2019)
29) A. Radford, K. Narasimhan, T. Salimans, and I. Sutskeve: "Improving Language Understanding by Generative Pre-Training," Open AI technical report (2018)
30) A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever: "Language Models are Unsupervised Multitask Learners," Open AI technical report (2019)
31) T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei: "Language Models are Few-Shot Learners," arXiv preprint arXiv:2005.14165 (2020)
32) C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu: "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer," arXiv preprint arXiv:1910.10683 (2019)
「自然言語処理コラム」トップに戻る