自然言語処理コラム ~深層学習モデル編~
深層学習モデル
ここでは、自然言語処理技術の中でも深層学習を使って単語や文章の多次元ベクトルを学習する深層学習モデルについて解説します。まずは第3次AIブームの火付け役となった「深層学習」について確認した上で、第3次AIブーム前半の代表的な深層学習モデルである「word2vec」「RNN」「LSTM」「seq2seq」「Attention」を取り上げて解説します。
深層学習
深層学習の概念は1980年代あるいはそれ以前から存在していましたが、2006年にトロント大学のジェフリー・ヒントン氏らの研究チームが重要な技術的進歩を発表したことで、これが第3次AIブームの引き金となりました。こここでは第3次AIブームにいたる歴史を振り返りながら、その中心的な技術である深層学習の概要を解説します。
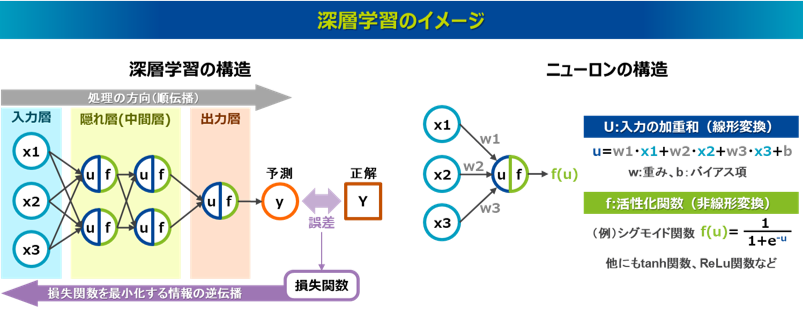
深層学習は、多層のニューラルネットワークを利用して、大量のデータから学習し、高度なパターン認識や予測を行う手法であり、ディープラーニング(Deep Learning)とも呼ばれます。ニューラルネットワークは入力層、隠れ層(中間層)、出力層で構成され、各層の処理では、前の層からの情報を線形変換と非線形変換をして次の層に引き継いでいます。線形変換とは前の層からの情報に重みをかけてバイアスを加えた加重和の計算です。非線形変換とはシグモイド関数やハイパボリックタンジェント関数といった活性化関数を適用する処理です。この2つの処理の組み合わせにより複雑な表現を可能にしています。特に隠れ層を多層構造にしたモデルは深層ニューラルネットワーク(Deep Neural Network, DNN)と呼ばれ、多くの隠れ層を持つことでより複雑な表現能力を獲得でき、性能が向上すると考えられていました。そしてヒントン氏らは1986年に、ニューラルネットワークの予測誤差の情報を出力層から入力層へ逆方向に戻しながら各層の重みとバイアスを更新する誤差逆伝播法(Backpropagation)を発表し7)、多層のネットワークでも効率的な学習が可能であることを示しました。
誤差逆伝播法は、ニューラルネットワークで出力された予測結果と実際のデータとの誤差を最小にするように各層の重みを更新する方法で、その誤差を表す損失関数を最小化するように各層の重みが勾配降下法により更新されます。勾配降下法では、まずどの方向に各層の重みを調整すれば損失関数の値を効率的に減少できるのか知るために、各層の重みに対する損失関数の勾配(偏微分)を計算します。勾配の計算では、合成関数の微分を行う連鎖律(Chain Rule)を適用し、出力層から入力層に向かって各層の重みにおける損失関数の勾配(偏微分)を逐次的に計算します。その各層の重みにおける勾配を集合したベクトル(勾配ベクトル)は損失関数の正の変化率が最も大きな方向を示すため、それを負にした逆方向のベクトル、すなわち損失関数が最も降下する方向に向けて重みを更新していく方法が勾配降下法です。なおこの更新は解析的には求められないので、反復計算を通じて近似的に損失関数が最小になる重みを見つけていきます。
2006年以前は深層ニューラルネットワークを実現する上で大きな問題が主に2つありました。一つは誤差逆伝播法における勾配消失と勾配爆発の問題です。誤差逆伝播法では、損失関数の勾配を求める際に、出力層から入力層に向かって各層における勾配を連鎖律で乗算して計算していきます。勾配消失は、各層を通じて微小な勾配が乗算され続けることで、勾配が急速に小さくなり、入力層に向かって勾配がゼロに近づく現象です。これにより、入力層に近い層の重みが更新されないという問題が生じます。勾配爆発は、逆に大きな勾配が乗算され続けることで勾配が急速に大きくなる現象で、重みの更新において安定性と収束性が損なわれる問題が生じます。もう一つの問題は過学習で、隠れ層が増えることでモデルが複雑になり、特定のデータに過剰に適合し、新しいデータに対する汎化性能の低下が生じます。これらの問題は、深層ニューラルネットワークの効率的な学習を妨げる主な要因となっていました。
そして2006年にヒントン氏らは深層学習における2つの重要な論文を発表しました。一つ目は深層ニューラルネットワークを高速に学習できるアルゴリズムに関するもので8)、もう一つはオートエンコーダを用いた次元削減と特徴抽出の方法です9)。オートエンコーダは、入力層と出力層を一致させたニューラルネットワークで、データの圧縮(エンコーダ)と復元(デコーダ)を学習して隠れ層で次元を削減する方法です。これを事前学習することであらかじめデータの重要な特徴を抽出しておき、それを後続の学習タスクに活用することで学習の効率化と性能の向上に貢献しました。さらに、このオートエンコーダは先述した2006年以前の2つの問題の緩和にも貢献しました。ヒントン氏らによって提案されたオートエンコーダの事前学習は、一度にすべてを学習するのではなく、各層ごとに分割して学習し、それを次の層に連携していきます。これにより誤差逆伝播法を実行する際は、勾配が全層を一度に通過するのではなく、段階的に伝播されるため、特に勾配消失の問題において影響を受けにくくなりました。なお、勾配爆発の問題も緩和効果はありますが、誤差が大きい場合の学習では依然として大きな勾配となる可能性はあります。またオートエンコーダは次元削減でデータの汎用的な特徴を抽出するため、過学習のリスクを低減させることができました。こうした深層学習の実現に関して重要な発表があった2006年以降、深層学習の研究は大きな発展を遂げることになりました。
その後、2012年9月に開催された画像認識の競技大会ILSVRC(ImageNet Large Scale Visual Recognition Challenge)で、ヒントン氏率いる研究チームが開発したAlexNet10)が圧倒的な性能を示しました。また同2012年6月にはGoogleがネット上の大量の画像データに深層学習を適用することで、コンピュータが猫を認識できるようになったと発表しました。特にこれらの深層学習モデルでは、1998年にヤン・ルカン氏らによって発表された畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)という、画像の局所的なパターンを効率的に認識できる手法11)が採用されました。このように2012年以降は、特に画像認識の分野を中心に、深層学習モデルが実用面において大きな成果を次々に上げていき、第3次AIブームが社会的にも認知されるようになりました。ヒントン氏はこうした深層学習の基礎を築いた功績が高く評価され、2024年のノーベル物理学賞を受賞しました。
ここからはこの深層学習モデルを自然言語処理の分野で応用して開発された各手法について解説していきます。
word2vec
word2vecは、大量のテキストデータ(コーパス)を用いたニューラルネットワークモデルで、単語のベクトル表現を得る手法であり、2013年にGoogleによって発表されました12)。このベクトルは分散表現、あるいは単語の埋め込みベクトル(Word Embedding Vector)と呼ばれ、単語の意味や類似性を捉えることができており、単語同士の演算もできます。
word2vecは、隠れ層が1層(さらに線形変換のみ)となるシンプルな深層学習モデルを採用しており(そのため一般的な「深層」モデルとは異なりますが)、CBoWとSkip-Gramの2つのアルゴリズムがあります。CBoW(Continuous Bag of Words)は、ある単語をその周辺単語から予測し、Skip-Gramはある単語からその周辺単語を予測します。つまり、word2vecは深層学習により大量のコーパスの穴埋め問題をひたすら解いており、この事前学習されたモデルを使うことで、単語のベクトル表現を容易に得ることができるというものです。なお学習の中で用いられる周辺単語の数は「ウィンドウサイズ」と呼ばれるパラメータとして指定し、5から10の範囲で設定することが一般的です。
word2vecの代表的なモデルには、たとえばGoogle Newsの約1000億語から成るニュース記事を元に学習された「GoogleNews-vectors-negative300」があり、約300万語に対して、入力した単語の300次元のベクトルが得られるモデルです。以下の図は、word2vecのイメージをするにあたって、仮に単純な4次元のベクトルで表現したものです。さらに、word2vecは線形なモデルであり、単語の意味的な演算をすることもできます。これは隠れ層が1層のシンプルなネットワーク構造から単純な線形変換を行い、単語は線形写像を通じて多次元のベクトル空間に配置されることで、得られる単語ベクトルが線形性を持つためです。たとえば王のベクトルから男のベクトルを引いて女のベクトルを足すと女王のベクトルになるといった演算が成り立ちます。
また、各文書に対して単語と同様に「文書ID」の要素を持たせてword2vecの学習を適用することで、単語と同様に「文書ID」のベクトル表現を得ることができます。この手法はdoc2vecと呼ばれ13)、文書全体のベクトルを生成することができます。
word2vecはこれまでの自然言語処理技術とは一線を画した革新的なもので、当時は一世を風靡しました。ただ、word2vecは単語の順序情報が欠落していて、同じ単語でも文脈によって意味が異なる場合は区別できないという課題が指摘されました。

RNN
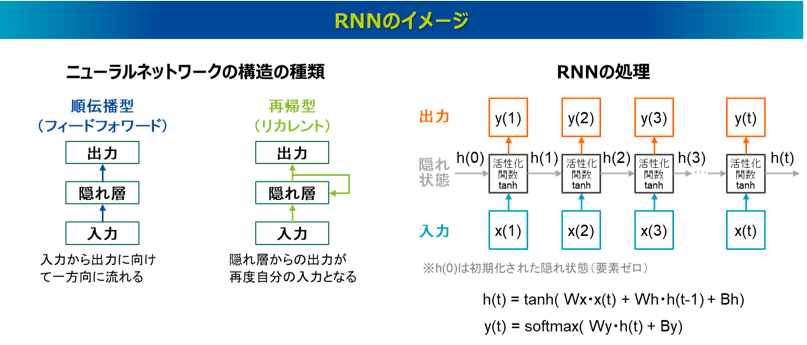
RNN(Recurrent Neural Network、再帰型ニューラルネットワーク)は系列データを処理するモデルですが、自然言語処理分野での適用では、文章を単語の系列データとして捉え、単語を一つずつ順番に逐次的に処理します。通常の深層学習はフィードフォワード型と呼ばれ、入力から出力に向けて一方向に流れますが、RNNでは、隠れ層からの出力が再度自分の入力に帰る再帰型(リカレント)の構造をしていることが最大の特徴です。
RNNは明確な起源を示すことが難しいですが、その歴史をたどると、最初にその考え方に影響を与えたのは、ジョン・ホップフィールド氏によって1982年に発表された論文であると考えられます14)。この論文ではフィードフォワード型のニューラルネットワークではなく、全結合型のニューラルネットワークによる処理方法が提案され、ホップフィールドネットワークと呼ばれます。なお、ホップフィールド氏はヒントン氏と並び2024年にノーベル物理学賞を受賞しています。その後シンプルなRNNの構造として、1986年に発表された出力層の結果をフィードバックするジョーダンネットワークや15)、1990年に発表された隠れ層の出力をフィードバックするエルマンネットワークがあり16)、これらは単純再帰型と呼ばれます。2010年にはトマス・ミコロフ氏によって自然言語処理の分野でRNNを適用し、次の単語を予測する言語モデルが発表され17)、2010年代初めから自然言語処理タスクにおいてRNNが盛んに適用されるようになりました。
RNNの処理は、各ステップの隠れ層における隠れ状態の情報が次の隠れ層の入力にもなる再帰的な処理をしています。より具体的な処理の流れは、t時点のステップにおいて、入力ベクトルのx(t)に加え、前の隠れ層からh(t-1)という隠れ状態ベクトルの情報を受け取り、それぞれに重み行列WxとWhを掛けます。それにバイアス項Bhを加えたものに活性化関数tanhを適用することで隠れ状態ベクトルh(t)を出力します。これは次の隠れ層に送る情報となります。さらにこの隠れ状態ベクトルh(t)に重みWyを掛けたものにバイアス項Byを加え、これに活性化関数softmaxを適用することで出力ベクトルy(t)を出力します。なお、それぞれのバイアス項は出力を調整するパラメータです。活性化関数tanhはハイパボリックタンジェント(Hyperbolic tangent)という関数で、これは入力値を-1から1の間に変換する関数です。類似する関数に入力値を0から1に変換するシグモイド関数がありますが、tanh関数はシグモイド関数よりも勾配が大きく、誤差逆伝播法における勾配消失問題が起きにくいとされます。また活性化関数softmaxはベクトルの各成分の合計が1となるように変換する関数で、各成分の値は0から1までの値を取るため、その出力は確率分布とみなすことができます。出力ベクトルy(t)は、学習データから得られた出力単語の候補群(語彙)における確率分布となっており、その確率の最も高い単語が最終的に選択されることになります。そしてその出力結果と正解の誤差情報から誤差逆伝播法によって各重みとバイアスのパラメータが更新されます。なおこれらのパラメータは各系列ステップ間で共通しています。
word2vecでは単語の順序情報を考慮することができませんでしたが、RNNでは過去の処理情報を保持して、それが現在の入力に影響を与える構造により、単語の順序(文脈)を考慮した処理ができることが特長となります。
しかし、長い系列データの場合、過去の情報を反映させるのが困難となる「長期依存性の問題」が指摘されています18)。これは、再帰的処理により隠れ状態が次の隠れ状態に連携されますが、長い系列でネットワークが深くなるとこの処理が繰り返され、誤差逆伝播法において勾配爆発や勾配消失が起き、過去の遠い情報を最適に保持できなくなるという問題です。勾配爆発では、再帰処理により、同じ重みが繰り返し乗算され、勾配が指数関数的に増加し、勾配消失では、再帰処理により、微分が0に近い活性化関数を繰り返し通過し、勾配が急速に小さくなります。
LSTM
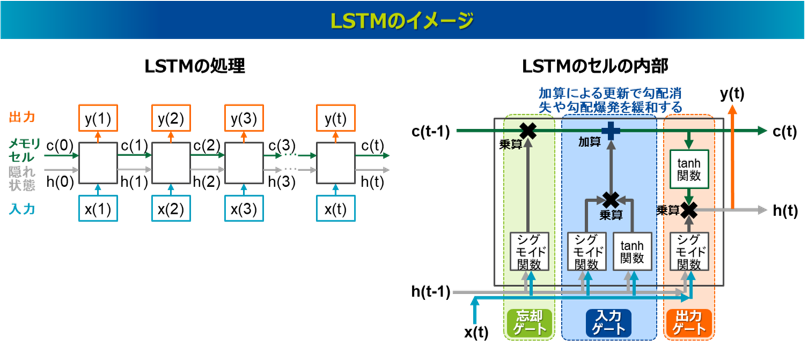
LSTM(Long Short-Term Memory、長・短記憶)はRNNと同じく系列データの処理モデルですが、RNNで課題となっていた長い系列の処理を可能とするモデルで、1997年に発表されました19)。RNNと同様にLSTMも自然言語処理の分野において盛んに適用されるようになったのは2010年代初めの頃からで、これは近年のビッグデータの利用やコンピュータの計算能力の向上が寄与しています。
LSTMの特徴は、RNNの隠れ状態h(短期記憶)に加え、メモリセルc(長期記憶)の情報がセルからセルに受け継がれる仕組みを取っていることにあります。このメモリセルcは記憶を長期に保持する機能を持っています。さらにLSTMの内部では、忘却ゲート、入力ゲート、出力ゲートという3つのゲート構造を持ち、各ゲートが情報の流れを制御しています20)。ここではそれぞれのゲートの特徴を述べるに留め、具体的な計算式の解説は割愛します。忘却ゲートは、受け継がれたメモリセルc(t-1)の長期記憶の情報のうちどれを受け継ぎどれを消去するか制御します。入力ゲートは、現在の入力x(t)と前の隠れ状態h(t-1)を使って、新しく記憶するべき情報の候補を生成し、どの情報を入力し記憶させるか制御します。出力ゲートは、次の隠れ状態h(t)と出力y(t)の情報を制御します。忘却ゲート、入力ゲート、出力ゲートでは、それぞれ最初に入力x(t)と前の隠れ状態h(t-1)に活性化関数のシグモイド関数を適用しています。シグモイド関数の出力は0から1の値を取るため、どの情報をどの程度通過させるか、あるいは通過させないかという、オン・オフの制御として機能しています。入力ゲートはこれに加えてtanh関数の適用があり、新しく記憶するべき情報の候補を生成しています。このtanh関数の処理はRNNで次の隠れ状態を出力するプロセスと同様です。また、tanh関数は-1から1までの値を取るため、符号を司る機能があり、その情報が正の影響を与えるか負の影響を与えるかも決定します。入力ゲートではこれにシグモイド関数の適用結果と掛け合わせる処理を行うことで、どの新しい情報をどの程度記憶させるか制御しています。そして入力ゲートでは、これと忘却ゲートで通過した情報を加えて次のメモリセルへと更新しています。最後に出力ゲートでは、通過したメモリセルの情報にtanh関数を適用し、それをシグモイド関数の適用結果と掛け合わせることで、長期記憶のうちどの情報を次の隠れ状態h(t)と出力y(t)に反映させるのか制御しています。
RNNでは隠れ状態の更新が重み行列の乗算と活性化関数の適用のみで行われ、これが長い系列で繰り返されることで長期依存性の問題が生じていました。一方、LSTMでは、3つのゲートでRNNと同様に重みの乗算と活性化関数が適用されますが、特に入力ゲートを通過する際には、忘却ゲートの結果と入力ゲートの結果を加算することでメモリセルが更新されます。この加算による更新メカニズムにより、必要な情報を長期間セル状態に保持し続けることができ、長期依存性の問題を(特に勾配消失において)緩和することができました。
このように、LSTMはRNNよりも長い系列が扱えるとされますが、実際は完全ではなく、RNNではうまく処理できる単語数が10語程度であるのに対し、LSTMでも約20語以上となると翻訳精度が劣化するといわれています21)。また、LSTMは計算コストが高いという課題もあります。
seq2seq
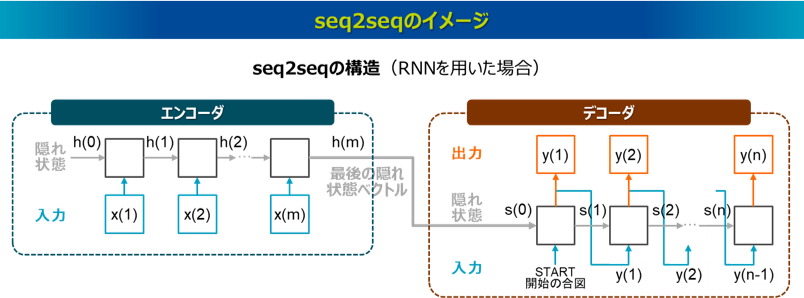
seq2seqは、系列データを系列データに変換するモデルで、2014年に発表されました22)。自然言語処理においては、seq2seqの代表例としてNMT(Neural Machine Translation)があり、NMTは機械翻訳を主な用途としたもので、これも2014年に発表されました23)。seq2seqはエンコーダ-デコーダモデル(Encoder-Decoder model)とも呼ばれ、文章をベクトルに変換するエンコーダ(seq2vec)と、ベクトルを文章に変換するデコーダ(vec2seq)が連結した構造を持ち、これにより機械翻訳などの文章から文章への変換を実現しています。
RNNやLSTMはそれ単体では、①seq2vec、②vec2seq、③入力・出力の系列数が一致するseq2seq(たとえば単語の品詞割当など)は処理できますが、機械翻訳のように系列数の一致しないseq2seqは処理できません。そこでこうしたseq2seqを処理するために、RNNやLSTMによるseq2vec(エンコーダ)とvec2seq(デコーダ)を連結して対応させます。seq2vecは、文章を一つのベクトルに変換する処理であり、RNNやLSTMの最後の隠れ状態ベクトルに該当します。一方、veq2seqは、一つのベクトルを文章に変換する処理ですが、RNNやLSTMでは、一つのベクトルを入力として単語を出力し、その出力された単語と前の隠れ状態ベクトルを新たな入力として次の単語を出力することで、最終的に文章を生成します。なお、RNNやLSTMがseq2seqのうち、単語の品詞割当など入力と出力の系列数が一致すれば処理できますが、機械翻訳など入力と出力の系列数が一致しないと処理できない理由は、RNNやLSTMは系列ステップごとに出力を生成する性質があるためです。
Atttention
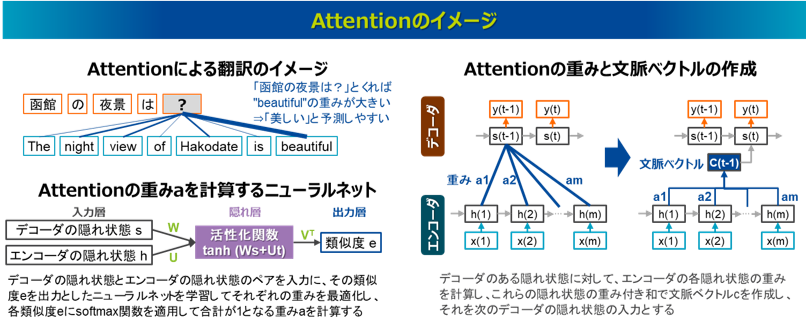
Attention(注意機構)は、seq2seqにおいて入力文章を出力文章に変換する際に、文章の中でどの単語に注目すべきかを判断する仕組みで、2014年にNMTの中で発表されました23)。
従来のseq2seqは、エンコーダの最後の隠れ状態である一つの固定長ベクトルだけがデコーダに連携されるため、受け渡しできる情報量に限界があり、長い系列ほど精度が落ちる課題がありました。これに対しAttentionでは、入力文章を出力文章に変換する際に、入力のどの単語に注目すべきか、あるいは無視すべきかを考慮できるため、入力と出力の依存関係を捉えることができ、精度の高い出力を実現することができました。遠い所にある単語も含め、入力文章に含まれるすべての単語を参照できるため、RNNやLSTMで課題となっていた長期依存性の問題も補完できる仕組みとなっています。
Attentionの仕組みを用いたモデルでは、デコーダの今の隠れ状態に対するエンコーダの各隠れ状態の注目度(Attention weight)を計算し、その重み付きの隠れ状態を足し合わせることで文脈ベクトルを作成し、これをデコーダの次の隠れ状態の入力として受け渡します。この処理をデコーダが新しい単語を出力する度に行い、新たな文脈ベクトルが作成され受け渡されます。なお、Attention weightはデコーダとエンコーダの隠れ状態のペアを入力とする単純なニューラルネットで計算されます。このニューラルネットでは、デコーダの隠れ状態とエンコーダの隠れ状態を入力としたときのそのペアの類似度eがスカラー値として出力されます。そこで得られた各ペアの類似度eにsoftmax関数を適用して合計が1となる重みaを計算すればそれがAttention weightとなります。このニューラルネットにおいて、デコーダの隠れ状態の重み行列、エンコーダの隠れ状態の重み行列、隠れ層から類似度eを出力する重み行列は、入力のソース文章と出力のターゲット文章のペアを教師とした学習過程を通じて、損失を最小化させる誤差逆伝播法によって最適化されます。
参考文献
7) D. E. Rumelhart, G. E. Hinton, and R. J. Williams: "Learning representations by back-propagating errors," Nature, Vol.323, No.6088, pp.533-536 (1986)
8) G. E. Hinton, S. Osindero, and Y-W Teh: "A fast learning algorithm for deep belief nets,” Neural Computation, Vol.18, No.7, pp.1527-1554 (2006)
9) G. E. Hinton, and R. Salakhutdinov: "Reducing the Dimensionality of Data with Neural Networks”, Science, Vol.313, No.5786, pp.504-507 (2006)
10) A. Krizhevsky, I. Sutskever, and G. E. Hinton: "ImageNet Classification with Deep Convolutional Neural Networks," Proc. of the 25th International Conference on Neural Information Processing Systems (NIPS 2012), pp.1097–1105 (2012)
11) Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner: "Gradient-based learning applied to document recognition," Proc. of the IEEE, Vol.86, No.11, pp.2278-2324 (1998)
12) T. Mikolov, K. Chen, G. Corrado, and J Dean: "Efficient Estimation of Word Representations in Vector Space," Proc. of the International Conference on Learning Representations (ICLR) (2013)
13) Q. V. Le, and T. Mikolov: "Distributed Representations of Sentences and Documents," Proc. of the 31st International Conference on Machine Learning (ICML-14) (2014)
14) J. J. Hopfield: "Neural networks and physical systems with emergent collective computational abilities," Proc. of the National Academy of Sciences (PNAS), Vol.79, No.8, pp.2554-2558 (1982)
15) M. I. Joradn: "Serial Order: A Parallel Distributed Processing Approach," ICS Report 8604 (1986)
16) J. L. Elman: "Finding structure in time," Cognitive Science, Vol.14, No.2, pp.179-211 (1990)
17) T. Mikolov, M. Karafiat, L. Burget, J. Cernocky, and S. Khudanpur: "Recurrent neural network based language model," ISCA Interspeech, pp. 1045–1048 (2010)
18) Y. Bengio, P. Simard, P. Frasconi: "Learning Long-Term Dependencies with Gradient Descent is Difficult," IEEE Transactions on Neural Networks, Vol.5, No.2, pp.157-166 (1994)
19) S. Hochreiter, and J. Schmidhuber: "Long Short-Term Memory,” Neural Computation, Vol.9, No.8, pp.1735-1780 (1997)
20) 杉山聡:『本質を捉えたデータ分析のための分析モデル入門』, ソシム (2022)
21) 佐藤大輔, 和知德磨, 湯浅晃, 片岡紘平, 野村雄司:『 BERT入門 プロ集団に学ぶ新世代の自然言語処理』, リックテレコム (2022)
22) I. Sutskever, O. Vinyals, and Q. V. Le: "Sequence to sequence learning with neural networks," Proc. of the 27th International Conference on Neural Information Processing Systems (NIPS 2014), pp.3104-3112 (2014)
23) D. Bahdanau, K. Cho, and Y. Bengio: "Neural machine translation by jointly learning to align and translate," arXiv preprint arXiv:1409.0473 (2014)