自然言語処理コラム ~前処理技術編~
前処理技術
自然言語処理の基本として、単語の出現頻度を使って文書をベクトル表現するための前処理技術について解説します。ここでは「形態素解析」「Bag-of-Words」「TF-IDF」を取り上げます。また、こうした前処理技術を基盤にテキストデータを分析する手法である「テキストマイニング」についても解説します。
形態素解析
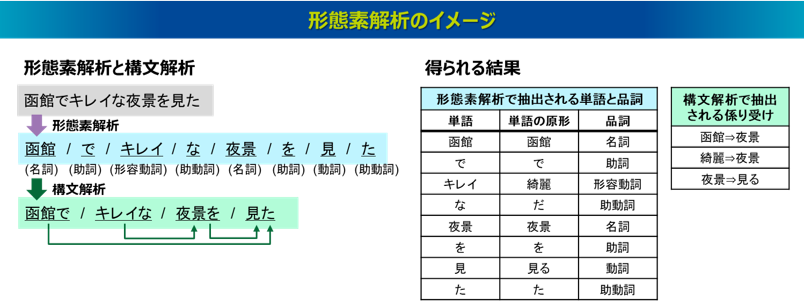
形態素解析とは、文章を単語に分割し、その単語の品詞を割り当てる技術です1)。正確には単語ではなく、形態素と呼ばれる意味を持つ最小単位の文字列として分割する手法ですが、実用面では、形態素ではなく単語の単位で分割されることが一般的です。補足として、単語とは一つ以上の形態素から構成される言語の単位です。単語と形態素の違いの例として、たとえば「観光地」という単語は「観光」「地」という2つの形態素で、「宿泊施設」という単語は「宿泊」「施設」という2つの形態素で構成されます。このように、日本語の意味情報を抽出するには最小単位の形態素よりも単語の方が適しているとされます。なお、英語の文章の場合は単語がスペースで区切られているため、日本語よりも形態素解析がしやすい言語といわれます。
形態素解析の発展した技術として構文解析というものもあります。構文解析とは、文法規則に基づいて文章の構造を解析し、単語間の関係性を識別する技術です。たとえば、主語と述語や、修飾語と被修飾語といった係り受け関係を抽出します。日本語の場合は単語ではなく文節を単位に係り受け関係を抽出するのが一般的です。文節とは、日本語を意味のわかる単位に区切ったもので、助詞や助動詞は名詞や動詞とセットで括られます。なお、日本の小学校では、文節は「~ね」で区切るものと教わることが多いかと思います。
これらの処理により、文章に含まれる単語とその品詞、また単語間(文節間)の係り受け関係を抽出することができます。なお、実際に抽出される単語や係り受けは、登録されている辞書によってそれぞれ原形に変換された形で抽出されることが一般的です。
形態素解析と構文解析には公開されたフリープログラムがあり、形態素解析ではJUMAN、ChaSen、MeCabなどが、構文解析ではKNPやCaboChaなどが広く知られています。
Bag-of-Words
Bag-of-Words(BoW)は、最もシンプルに文書をベクトル化する手法です。形態素解析によって文書に含まれる単語を抽出し、各文書にどの単語が何回出現したのかをカウントする手法で、その出現頻度という数値によって文書一つひとつをベクトルとして表現しています。Bag-of-Wordsのベクトル表現は「文書×単語」という行列形式のデータで考えると分かりやすいです。一つの行に一件の文書を、一つの列に一つの単語を取ったとき、各セルの値はその文書内におけるその単語の出現回数を示します。これは最もシンプルな文書のベクトル表現ですが、この処理だけでもテキストデータのさまざまな定量分析が可能となり、とても強力な処理手段です。
一方、シンプルが故の課題も存在します。たとえば、Bag-of-Wordsではすべての単語は同等に扱われ、その単語が全文書で見たときにどれくらい重要であるかは認識されません。単語の位置や順序、使われ方、文脈における意味といった情報も保持しておらず、その文字列の出現頻度のみの情報となっています。また、単語の種類の数がベクトルの次元数となるため、高次元なデータとなって複雑で、計算処理が難しくなるという課題もあります。

TF-IDF
Bag-of-Wordsにおいて、単語の重要度が考慮されていないという課題に対応した前処理の手法にTF-IDFがあります。TF-IDFは、各文書における単語の重要度を数値化する処理で、TFという指標とIDFという指標の積によって計算されます。
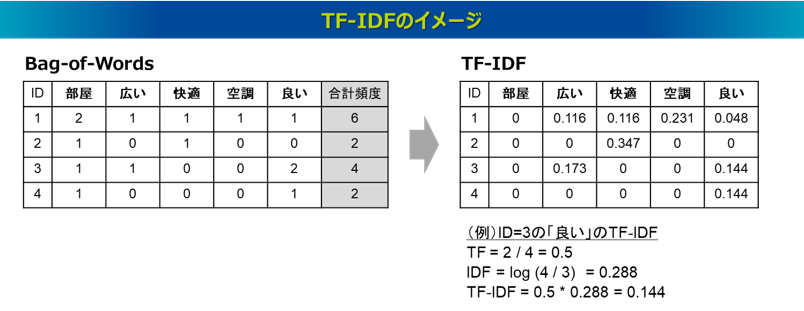
TF(Term Frequency)は、各文書の中における単語の頻度を示す値で、頻度が多い単語ほど重要であると判断します。なお、文書の長さの影響を受けるため、その文書で出現する全単語頻度で除して正規化することが多いです。一方、IDF(Inverse Document Frequency)は、ある文書で頻出する単語でも、それがどの文書でも頻出するなら重要とはいえないと判断する指標です。一般的には、log(全文書数 / 単語wが出現する文書数)で定義され、多くの文書で現れる単語は値が小さくなり、特定の文書にしか現れない単語は値が大きくなるように調整されます。以下の図はBag-of-WordsのデータからTF-IDFの処理をした例です。
TF-IDFは、テキストデータの分析ではよく用いられる前処理の手法で、たとえば文書間の類似度の分析では、TF-IDFの処理をしたベクトルを使って、そのcos類似度を計算することが多いです。
テキストマイニング
テキストマイニングは大量のテキストデータから、その文書に含まれる単語を抽出し、単語をベースに文書に記述されている傾向を把握するデータマイニング手法です。形態素解析と構文解析の2つを基本技術としていることが一般的で、これによって処理されたBag-of-Wordsのベクトルデータを使って、テキストという定性的なデータでも定量的に集計したり統計的な分析を可能にします。
現在では多くのテキストマイニングツールが存在し、自然言語処理の専門知識がなくても、分かりやすいインタフェースで直感的な操作が可能で、テキストデータを活用したいビジネスの現場では人気のある分析ツールといえます。たとえば、無償のツールでは、立命館大学の樋口耕一教授が作成したKH Coderやユーザーローカル社のAIテキストマイニングなどが、有償のツールでは、NTTデータ数理システム社のText Mining Studioやプラスアルファ・コンサルティング社の見える化エンジンなどが知られています。
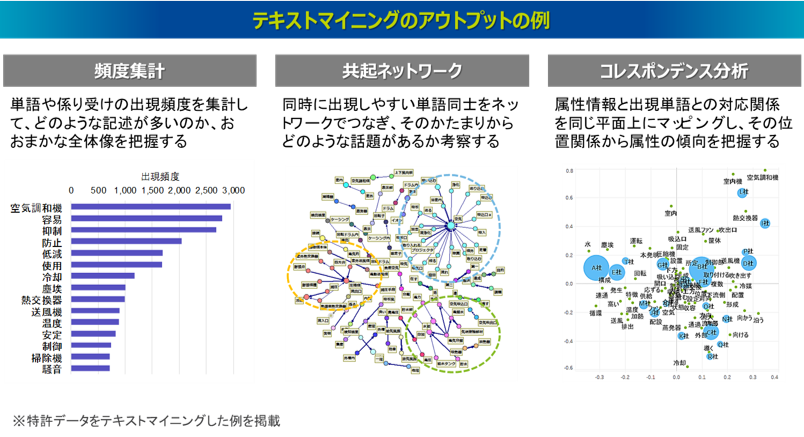
以下の図はテキストマイニングのツールでよくある分析アウトプットの例を示したものです。もっとも単純な分析機能は単語の頻度集計です。形態素解析によって抽出された単語や、構文解析によって抽出された係り受け表現の出現頻度を集計しランキングすることで、分析対象としているテキストデータの文書情報では、どのような記述が多いのかという全体像を把握します。また、1 件の文章の中で同時に出現しやすい単語同士をネットワークでつなぐ共起ネットワークという分析機能があります。単語の頻度集計では、それぞれの単語が独立して集計されるため単語間のつながりが分かりませんが、共起ネットワークではつながりのある単語のかたまりが可視化されます。こうしたネットワークの結果から、このテキストデータの文書情報ではどのような話題が形成されているのか考察できます。さらに少し高度な分析機能として、コレスポンデンス分析(あるいは数量化Ⅲ類)というものもあります。これは、テキストデータに紐づく属性情報(たとえばアンケートデータであれば回答者の性別・年代、特許データであれば出願人や出願人といった属性情報)と文書情報内の出現単語との対応関係を同じ平面上にマッピングしたものです。そのマップの属性と単語の位置関係からそれぞれの属性の記述傾向を把握できます。
このようにテキストマイニングは、テキストデータの文書情報に含まれる単語や係り受け表現を抽出することを基本とし、その単語や係り受けをベースに集計したり、属性情報とも絡めて統計解析を実行することで、テキストデータ全体の記述傾向を可視化し、現状を把握できる手法となります。テキストマイニングはビジネス現場でもよく活用されており、たとえば以下のような活用例が挙げられます。テキストマイニングでテキストデータを分析し活用することは、ビジネスの現場の課題解決において価値の高い取り組みとなっており、たとえ使用されている自然言語処理技術は古典的な技術であっても、その分かりやすさからくる有用性は高いといえます。

参考文献
1) 金明哲:『テキストアナリティクス』,共立出版 (2018)